

Arroyo pipelines are built using analytical SQL. But unlike traditional SQL databases and query systems, Arroyo operates on streams of data that are never complete.
So what does it mean to apply SQL operations like joins and group-bys on potentially infinite data? In this post we’ll walk through the two common answers to that question, and how you can apply your existing SQL knowledge to building real-time data pipelines.
But first let’s talk about some math
SQL is a relational algebra. That’s a fancy math way of saying that it’s a collection of formalized operations that follow certain rules, operating on a class of sets. Specifically it operates on sets called relations, which is a fancy math word for “table.” SQL includes standard set operations like union and intersection, as well as some specialized ones like projections and joins.
In a traditional SQL database like MySQL or Postgres, these operations have straightforward semantics1. For example,
SELECT count(*) from orders WHERE price > 100will return the number of rows from the orders table where the column price is greater than 100.
These operations are straightforward to define because the underlying data is bounded. We can look over all of it and return the correct result.
But when we try to apply SQL to streams of data, we have some immediate problems. Unlike the fixed data in a database, a stream represents an ever-increasing number of rows. The underlying math, relational algebra, operates on finite sets but now we have potentially infinite sized sets2.
Whereas that count(*) query can return as soon as it’s scanned over all orders3, if we’re operating on an infinite stream we’ll have to wait until the stream is complete, which might be a while!

Tables are bounded, allowing us to compute aggregations. Streams are unbounded, so the query never finishes.
Most users don’t want to wait until the end of time for their queries to return results, so clearly we’re going to need some new formalisms if we want this to be useful.
Dataflow semantics for streaming SQL
So how can we usefully apply SQL to potentially infinite streams of data? There are two common answers. We’ll start by walking through the traditional approach which I’ll call Dataflow semantics, because it’s based on the model described by Google’s Dataflow paper.
For each of these examples, we’ll be querying off streams that have the following definition:
CREATE TABLE orders (
id INT,
time TIMESTAMP,
customer_id INT,
product TEXT,
store_id INT,
price FLOAT
);
CREATE TABLE pageviews (
id INT,
time TIMESTAMP,
customer_id INT,
page TEXT
);Let’s start with a query that has a straightforward interpretation.
SELECT price * 1.08 AS total_price
FROM orders
WHERE store_id = 5;Each record that comes in to the system produces a new record that’s been transformed in some way (in this case adding in tax to the price) and filtered using row-local data. The context for this operation is just a single record, so there’s no need to wait.

For queries that operate on individual rows, we can process them as records arrive
Simple stream processors focus on this sort of stateless, record-at-a-time processing. But many useful queries do not fit into this mold.
Windows
Let’s extend our SQL with a core concept for streaming data: time.
Streaming applications often involve processing data within windows, which are ways of aggregating over streams of records in time. Common windowing strategies include sliding windows which overlap according to a defined slide (see this post for more details), and tumbling windows which are fixed-size and non-overlapping4.
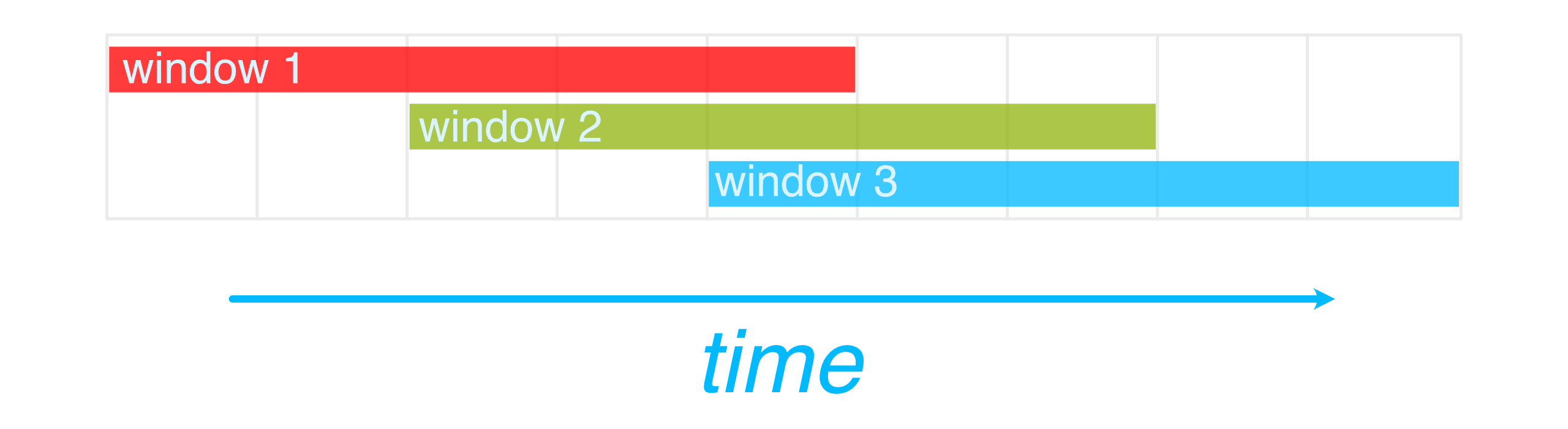
Sliding windows are fixed size and overlap according to their slide
Let’s say we want to compute the total sales for each store over a 1 hour period. In standard SQL we might do something like this:
-- this query will never return
SELECT date_trunc('hour', time) as hour, sum(price) as sales
FROM orders
GROUP BY hour, store_id;Now we have a GROUP BY, which is supposed to create a row that contains all of the records with that particular key (hour, store_id). But data for that key may come in at any point in the future!
One thing to note is that the fields we’re grouping by could be anything—as far as SQL is concerned, the fact that we’re grouping by time isn’t special. But in real-world streaming systems we know that our data tends to come in more or less in order, and typically with some bound on lateness.
In other words, we don’t usually get an event from a second ago, then one from a week ago, then one from yesterday. We can usually define some fixed lateness δ such that nearly all events received at clock time t will have occurred between t and t - δ5.
We can use this idea (expressed as something called a watermark) to make these window queries work in practice. We just need to introduce a notion of completeness—in other words, we need to decide that we’ve seen all of the data for a particular window so that we can process it.
To allow users to opt-in to that behavior, we might introduce some special SQL functions, hop and tumble, which implement sliding and tumbling windows respectively.
-- this will actually emit records because we've placed a bound on time!
SELECT tumble(interval '1 hour') as hour, sum(price) as sales
FROM orders
GROUP BY hour, store_id;Now this query can run because the special tumble function is watermark-aware. When the watermark passes the end of the window, we know not to expect any more data within that window, so we can process it and emit the result.
Joins
JOIN presents a similar problem to GROUP BY—FROM A JOIN B must consider all pairs of tuples from A and B to emit the matches—which again means waiting forever.
We can use the same solution: combine JOIN with a window to get us a notion of completeness.
CREATE VIEW pageviews_agg as (
SELECT count(*) as views, customer_id, tumble(interval '1 hour') as window
FROM pageviews
GROUP BY window, customer_id
);
CREATE VIEW orders_agg as (
SELECT count(*) as orders, customer_id, tumble(interval '1 hour') as window
FROM orders
GROUP BY window, customer_id
);
SELECT O.window, O.customer_id, C.views, O.orders
FROM orders_agg as O
LEFT JOIN clicks_agg as C ON
C.customer_id = O.customer_id AND
C.window = O.window;This join collects data on both sides for each window, then once the window has closed, pairs all of the matches and emits them to the aggregation. This requires that each side of the join be defined on the same window.
There are other types of non-windowed joins that can be usefully defined, for example left joins where the right side is aggregated and the left side emits per-record; this can be useful for pulling back aggregated histories for keys that get emitted on every important event.
But more powerful joins will require some different semantics.
Update tables
So far we’ve been talking through how to apply SQL to streams by adding in semantics around time, which allows us to determine completeness. This is the traditional approach, taken by systems like Flink and Dataflow.
But there’s another perspective on this problem, as exemplified by systems like Materialize and RisingWave. What if we throw out notions of completeness entirely, and instead try incrementally converging on the answer?
In this model the query logically describes a new table which eventually will contain all of the rows that it would if we had run this over the entire dataset at rest. In Arroyo, we call this an “update table,” because it is incrementally updated as new data comes in (in Materialize this is called a “materialized view.”)
Let’s take a concrete example. Here’s that tumbling window query that gave us trouble before:
SELECT date_trunc('hour', time) as hour, sum(price) as sales
FROM orders
GROUP BY hour, store_id;We previously made this tractable by replacing the date_trunc function with a special, time-aware tumbling window function. Using update tables the original query now has a defined semantic: on every event, it will recompute some row based on the store_id and hour and output that update.

Update tables are incrementally updated as new records come in, and ultimately converge on the correct answer
In fact, we can handle essentially any SQL query using these semantics! However performing this incremental processing efficiently is not always possible.
That query is simple, but there are some details we ignored. We’ve eliminated time-based semantics, so we can update rows and converge on the correct answer no matter what order records come in. But this implies that we store the underlying data forever. Maybe a month from now we get a row from last Tuesday, and under these semantics we’re still supposed to be able to update the value and emit a new result.
And so again we need to introduce a bit of impurity into our defined SQL semantics: an implicit time-to-live (TTL), which will evict old data from our state. In Arroyo this defaults to 24 hours, but can also be configured at the system level; in Flink it’s similarly a config option, while Materialize relies on filters with a special mz_now() function.
In practice, pipelines need to bound their input data in time so that they do not end up storing it for their entire lifetime.
Consuming updates
So far we’ve been talking about the semantics of update tables within the stream processor. But how do you actually use them?
Internally, update tables are represented by a stream of update operations—appends, updates, and deletes. The terminal update stream—representing the result of the entire query—can simply be written to a sink like Kafka and be consumed directly.
For example, Arroyo supports writing the update stream as Debezium-formatted JSON which can be applied by Debezium to a SQL database like MySQL and Postgres. It looks like this:
{"before": null,
"after": {"hour":"2023-07-24T23:00:00","store_id":5,"sales":1000},"op":"c"}
{"before": null,
"after": {"hour":"2023-07-24T23:00:00","store_id":7,"sales":1372},"op":"c"}
{"before": {"hour":"2023-07-24T23:00:00","store_id":5,"sales":1000},
"after": {"hour":"2023-07-24T23:00:00","store_id":5,"sales":1300},"op":"u"}
...Update streams can also be consumed internally by connectors to apply transactional updates directly to sink systems. For example, you could have a Postgres sink that keeps a Postgres table synchronized with the state of the virtual table represented by the query.
Too many SQL semantics
Today the most sophisticated streaming SQL systems like Flink and Arroyo support both dataflow semantics and update table semantics, and can even combine them in the same query.
That leaves the question: when does it make sense to use one over the other, and do we really need both?
Dataflow semantics (using watermarks to determine completeness) is very useful for integrating streaming into applications, where timeliness is generally more important than absolute completeness. For example, an anti-fraud system has to decide as quickly as possible whether to allow an order to go through or not, and it’s much easier to build that when the streaming system itself can tell you when it has a result.
For streaming analytics, update semantics can be more valuable. Queries can generally be ported directly from batch systems and they have the property that—so long as you wait long enough—they will have converged to the correct, complete answer.
Or in table form:
| Dataflow Semantics | Update Semantics | |
|---|---|---|
| Completeness | Relies on a watermark to determine when a window is complete; data received past the watermark is dropped | Tables are incrementally updated and eventually converge to the complete result; in practice TTLs are used to constrain state sizes |
| SQL support | Generally requires that aggregations and joins are performed over a window | Nearly all SQL can be supported |
| Efficiency | Allows very efficient windowing implementations | Maintaining old data in state takes more resources, rows may need to be updated many times |
| Usage pattern | Generally push-driven; the streaming system pushes out results to consumers when they are ready | Generally pull-driven; consumers need to decide when they will query the results and determine for themselves whether data is complete enough |
| Use cases | Real-time application features, monitoring, fraud, ETL | Analytics, billing, integration with RDBMs |
So which one is best? It depends on what you’re doing. And if you use a system like Arroyo, you get both out of the box.
Footnotes
This post is going to use the word “semantic” a lot, which is a programming-language theory term that describes the behavior of a particular programming language construct. You can think of the “semantics” of a language as encompassing a rigorous mathematical definition of how it behaves. ↩
While relational algebra is in fact definable on infinite sets, the application to real databases is not very obvious. Queries over infinite sets would take infinite time to complete. ↩
Of course, real databases are implemented more efficiently than these schematic descriptions. ↩
There are many other possible ways of dividing up streams, including session windows which are not fixed size but depend on time gaps in the data. ↩
A fixed-lateness strategy is the simplest of many possible watermark strategies, but it’s what is used in most real-world applications. ↩