

Arroyo is a distributed stream processing engine that allows users to ask complex questions of their event data in real-time by writing SQL queries. Specifically, it’s a stateful stream processor, which means that it’s able to store data about previously seen events, enabling features like joins, windows, and aggregations. Adding stateful capabilities provides a lot of power, but also comes at a cost in complexity and operational overhead—which systems like Arroyo have spent a lot of engineering energy to overcome.
So what is this state stuff all about? And why is it (sometimes) worth paying the cost in complexity to use it?
Table of Contents
Stateless stream processing
Many stream processing engines are stateless, which means that they process each event in isolation1 and don’t have the ability to remember information about the data they have previously seen.
The truth is that state is terrible. Storing state makes systems 10 times harder to run reliably. The reason a database is so much harder to operate than a typical microservice is, well, all of that state. This distinction is so important that typically you see the word “stateless” right before the word “microservice.”
In stream processing, statelessness also goes hand-in-hand with a property that I’ll call map-only. This means that there are no operations that require reorganizing (“shuffling”) or sorting data2; only operators that are like “map” or “filter” (in SQL terms, SELECT and WHERE) are supported. In particular, GROUP BY , JOIN, and ORDER BY can’t be implemented.
Stateless, map-only streaming systems have many nice properties.
- They’re trivial to run in cluster systems like Kubernetes or serverless frameworks like AWS Lambda
- Easy to scale (just add more workers)
- Failures are fine-grained; if a worker node fails, other nodes aren’t affected 3
- Recovery is fast—there’s no state to restore
If your needs fit within these constraints (no aggregation, no shuffles), you should run a stateless stream processor, like Vector. Often for stateless problems you don’t even need a stream processor. You can often get away with a service that consumes from your stream (Kafka, SQS, etc), performs your transformation logic, and writes the results to your sink.
You often find these use cases in observability pipelines. For example, collecting metric data from hosts, performing some stateless transformation on them, then sending them to a metric database. Or for logging pipelines where you need to do some stateless rewriting (filtering, redacting sensitive data, converting the format, etc.).
An example SQL query that can be implemented in a stateless stream processor looks like this:
SELECT timestamp, redact(log_text)
WHERE log_level = 'ERROR';Adding in state
But many business problems require remembering things about past events—that is, state. And with more complex computations we often need to repartition (aka shuffle) the data across the nodes in our processing cluster.
Stateful aggregations
Let’s walk through an example that shows how shuffling and state can enter into streaming applications: an e-commerce website that needs to detect and stop credit card fraud.
To detect fraud, we’ll want to look at a bunch of signals (or features in machine-learning terms) that could be correlated with fraudiness. For example, one effective feature is “how many failed transactions does this user have over the past 24 hours.”
In Arroyo SQL, this could look like
SELECT user_id, count(*) as count
FROM transactions
WHERE status = 'FAILED'
-- "hop" is arroyo sql for a sliding window
GROUP BY user_id, hop(interval '5 seconds', interval '24 hours');SQL queries are translated into a graph of operators, each of which is responsible for handling some part of the query logic.
Simplified a bit, the graph for this query looks like this:

The sliding window aggregation is going to count how many failing events there are for each user id. In order to produce that total count, we need to ensure that all events for a particular user (say “bob”) end up on the same machine for processing4. In the context of streaming, this is usually called shuffling, and in SQL is introduced any time we have a GROUP BY.
By rearranging the data such that all of the “bob” events end up together, we’re able to answer questions about all of bob’s activity:
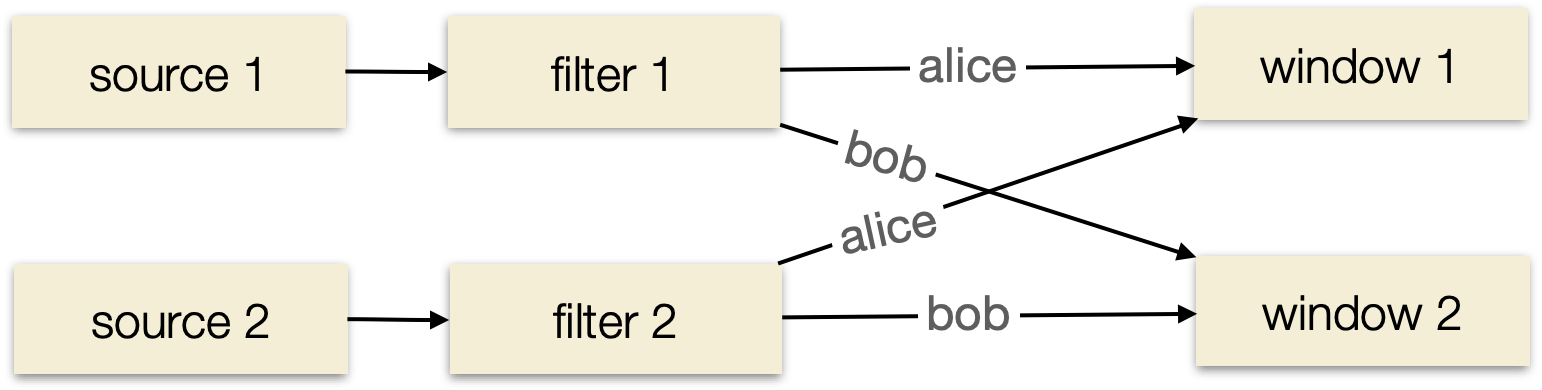
In this example, we have a parallelism of 2, so two subtasks for each logical operator. Because data for a particular user (say, bob) may come in on any source task, we need to repartition (shuffle) the data stream before performing our stateful window operation.
But to actually produce that count over 24 hours, we need to remember those events until the end of our window, so that we’re able to evict data once the 24 hours has passed. In the simplest version of this, we store all events received for “bob” for 24 hours, then every 5 seconds we read through all of those events and produce the count; when an event passes our 24 hour window we evict it. (In Arroyo, we implement sliding windows much more efficiently than this, with some very cool algorithms. You can read more about that in this post). This is state, and is necessary for any query that needs to compute aggregates over time.
State in ETL pipelines
In practice, many streaming use cases require state and shuffles. Let’s take a non-obvious example where state is very helpful: ETL’ing events into a data lake (for example, in S3). This may seem like a simple, stateless transformation: receive each event, apply some stateless transformation, and write it to S3.
And that will work for a small number of events. But as your event volume grows, this approach will lead to performance problems both when writing data to your data lake and when later querying the data.
High-throughput writes to object stores like S3 require batching data, typically 8MB or 16MB, and uploading that as a single part of a multi-part upload. Simply batching data doesn’t necessarily require your processor be stateful5.
However, for good query performance you may need to reorganize the data in some way that corresponds to your query patterns. For example, many data lakes have many different types of events and typically queries are over just one or several event types. In this case you will get much better performance and lower query costs by writing events to separate files. But if each processor writes a file for each event, you will end up with a huge number of files which will also hurt query performance.
A solution is to use a stream processor that can shuffle the data by event type so each event goes to a single processing node, and use state to buffer the in-progress writes. (We previously wrote about how Arroyo solves this problem of efficiently and transactionally ingesting data into S3.)
Storing state
We’ve been talking about state as an abstract concept. It’s stuff we need to remember in order to compute our query. But… what is it, physically? Where is it stored, and how?
Stateful streaming engines answer these questions very differently. Surveying some popular options, in roughly historical order:
- Apache Flink stores state either in memory or using RocksDB, an embedded key-value store. With both options, all state is stored locally on the processing node.
- ksqlDB / Kafka Streams stores some state in Kafka, while window state is stored in either memory or RocksDB.
- Rising Wave stores state remotely in S3 using a storage system called Hummock, with an in-memory cache on compute nodes.
- Arroyo stores state in memory on processing nodes, with a flexible programming model that allows operators to structure their state in space and time efficient ways for their particular access patterns. Arroyo Cloud stores state remotely in a distributed KV database (FoundationDB) with a local cache.
Early stateful systems like Flink and ksqlDB were designed at a time when memory was expensive and networks were slow. They relied on embedded key-value stores like RocksDB in order to provide large, relatively fast storage. However, in practice many users rely on the in-memory backend due to the complexity of tuning RocksDB.

LSM trees are a popular option for storing state in streaming systems. They provide fast writes and can support asynchronous and incremental checkpoint. However, they are complex to tune and require Disk IO-intensive compaction operations to maintain performance. Diagram courtesy of Wikipedia.
In Flink, the underlying storage is abstracted out from the implementation of operators behind high-level interfaces that provide persistent data structures like lists and maps. This allows operators to work for various state-backend implementations, but limits optimizations.
While Flink supports storing TBs of state in RocksDB, in practice this proves operationally difficult because of the need to load all of the state onto the processing nodes. Newer systems like Rising Wave and Arroyo have adopted remote state backends that allow only live data to be loaded onto the processing nodes which enables much faster operations at large state sizes.
Consistent checkpointing
Now that our processing nodes are stateful, what happens if they crash?
This is the core operational difficulty of stateful workloads. For databases, handling backups, migrations, and recovery can be a full time job. For many companies this involves manual and ad-hoc effort6.
And while that can work for streaming pipelines if you have just a few of them, once you have 10 (or 100) pipelines running you are going to need a process that is fast, reliable, and automated, covering operations like:
- Recovering from failure (program crash, bad hardware, network partition, etc.)
- Moving workloads to other hosts7 (for cluster compaction, software updates, etc.)
- Rescaling (adjusting for daily/weekly traffic patterns and usage spikes without over-provisioning)
- Deploying new versions of your code or framework
We need to be able to push our state somewhere else, so that if we lose a node we’re able to restore it and recover our state. For streaming systems that aim for exactly-once processing, there’s an additional wrinkle: we need to be able to do this consistently across our distributed system. We need a way to checkpoint (aka snapshot) each operator’s state such that the following invariant holds:
Or in simpler terms, for every event that is read in from our source, we need to snapshot a consistent version of the state such that each event has either been seen (and caused state updates) for every operator in our pipeline, or for none of them.
How does this work? Arroyo, Flink, and Rising Wave rely on a very clever idea from all the way back in the 80s. It’s called the Chandy-Lamport algorithm, and we’ll cover the details of how this works in a future post.

This diagram (courtesy of the Flink Docs) shows how checkpoint barriers flow through the dataflow graph. The barriers are used to ensure that all events prior to the barrier have been processed before the barrier is allowed to pass through the graph.
Beyond the algorithm, there are concerns that are more systems-y.
We have data locally—typically in memory, or possibly on disk in a LSM-tree—that we need to ship to remote storage (originally a distributed filesystem like HDFS, but nowadays more often an object store like S3).
Ideally, this uploading process should be
- Asynchronous: we don’t want to block processing new records while we’re checkpointing our state. Ideally we’d like to do a fast in-memory snapshot (using a copy-on-write data structure, for example) that we can upload in the background while processing continues.
- Incremental: we want to upload just the new or changed data, and not all data for the pipeline.
Together, these allow us to have frequent, fast checkpoints that limit how much we need to recover on failure.
For example, Arroyo checkpointing is asynchronous and incremental, and can transparently checkpoint every 10 seconds for most applications. This means that on failure, Arroyo only needs to replay 10 seconds of data to recover the pipeline.
Wrapping up
Stateful stream processing engines are complex to build and operate. Adopting a stateful engine can require some upfront cost in learning how to operate it successfully—particularly for older engines like Flink that were developed before the current era of cloud and serverless computing.
But in return for that extra work, you get a system that is able to solve all classes of streaming problems—from simple stateless transformations, to pipelines involving complex windows, joins, aggregations, and key partitioning. And with consistent checkpointing algorithms, these engines are able to do all of this while maintaining exactly-once semantics, which can simplify the rest of your architecture.
Modern engines like Arroyo and Rising Wave are are also adopting newer techniques in state management, like tiered and remote storage, to reduce their effective statefulness and simplify operations.
For users looking for the power of a stateful stream processing engine without the operational complexity, there is Arroyo Cloud. It provides a fully serverless experience for complex streaming applications.
Footnotes
Some of these engines support limited state, like Vector’s buffering capabilities, but don’t support long-term or general purpose state storage. ↩
Some “lightly stateful” stream processors push shuffling operations upstream by relying on something like keyed Kafka partitions to group data together. ↩
This may not be entirely true depending on the source you’re reading from. For example, Kafka uses consumer groups to assign partitions to worker nodes. If a node failure, the partitions need to be rebalanced among the remaining members of the group, which can cause some processing downtime. ↩
The real version of this graph splits the sliding window into two parts; first we do a local aggregation, then shuffle, then do a final aggregation. Doing the aggregation in two phases reduces the amount of data we need to shuffle and can greatly improve performance. ↩
For example if your events are in Kafka, you can batch in-memory on your processing node until the desired part size is reached, waiting to commit the offset until you upload the part. If your node crashes, you can recover from the last committed offset and thus ensure no data loss. ↩
And often it’s the case that recovery processes are…discovered…in the moment, when the database is down, and the entire company is on fire. Not speaking from personal experience or anything here. ↩
Much of modern, large-company infrastructure was built by service engineers who believe that all workloads are stateless services that can be easily rescheduled on a whim with no user impact. This is usually charmingly naive, but if you can achieve it you get a bunch of nice properties. You’re able to compact your cluster resources regularly and automatically (avoiding expensive fragmentation of unused CPU/memory), and ensure that your underlying VMs are always up to date. ↩