

Arroyo is a stream processing engine; users write SQL to build real-time data pipelines. Now SQL is a great language for data processing, supports a huge variety of functions, and is adaptable to a wide variety of use cases including streaming data.
But as powerful as SQL is, sometimes there’s a computation that just isn’t easy (or possible) to express as a SQL expression. Maybe you need to parse a custom binary data format, implement a complex aggregation strategy, or call some pre-existing business logic.
For these cases many SQL engines support user-defined functions (UDFs), which come in several forms: scalar UDFs, UDAFs (aggregate functions, which operate over multiple rows), and UDWFs (window function, which can reference other rows).
UDFs make SQL engines extensible. They let users customize the system to their needs. This is particularly important for us, as a small startup that can’t build all of the functionality every user might want ourselves. But Arroyo is built in Rust—which likes to build static binaries. How can we support dynamic, user-defined behavior?
Historically, Arroyo supported UDFs via static, Ahead-of-Time (AoT) compilation, but with Arroyo 0.10 dropping AoT in favor of interpreted SQL runtime built around Apache Arrow and DataFusion, we needed a new strategy. The result is a dynamically-linked, FFI-based plugin system with support for sync and async functions.
You can see how this looks from a user perspective in our docs, or jump into the code. The rest of this post will dive deep into how we ended up with this design, the technical details behind it, and what you need to know to build your own FFI-based plugin interface in Rust.
Table of Contents
The history
Arroyo has supported UDFs since 0.3 and UDAFs since 0.6, and it’s become one of our most widely used features. We supported UDFs very early on in part because they were so easy to build into our architecture. Until our recent 0.10 release, we relied on ahead-of-time compilation for our pipelines. In short, we would generate Rust code with the data types, expressions, and graph structure of the pipeline, then compile that into a binary which would execute it against the data streams.
In this paradigm, supporting UDFs was straightforward. For example, a SQL expression like
LENGTH(CAST((counter + 5) as TEXT))would be compiled into something like the following Rust code1:
(counter + 5).to_string().len()Since we’re just generating Rust code, we can slot in a user-provided Rust function easily.
The Arroyo UDF editor
The way it worked was this: the Arroyo UI provided an editor where users could write UDF functions as Rust code. A UDF function looked like this:
pub fn square(x: i64) -> i64 {
x * x
}UDFs could also include a special comment at the top to add additional dependencies, in Cargo.toml format:
/*
[dependencies]
regex = "1"
*/When a user runs a pipeline with this UDF, the system would parse the function definition, pull out the arguments and return types, map them to the corresponding SQL data type, and register it with the SQL planner.
After planning comes codegen. UDFs source code would be written directly to a lib.rs file in a crate, alongside another crate with generated wrapper code, which would then be added a dependency to the pipeline crate. At this point, it’s a normal, statically linked Rust function that could be called like any other within the generated expression code.
Living dynamically
For Arroyo 0.10, we knew we would need a different strategy, since we were no longer building a static pipeline binary. Instead, expressions would be executed at runtime by a tree-walking interpreter, which would need some way to call out to the UDF code without having it available at compile time.
At this point, we started looking at prior art in the Rust world, and came across this great blog series on Rust plugins from Mario Ortiz Manero, which we’re very indebted to. Unfortunately, it quickly became clear that this was not a solved problem in Rust.
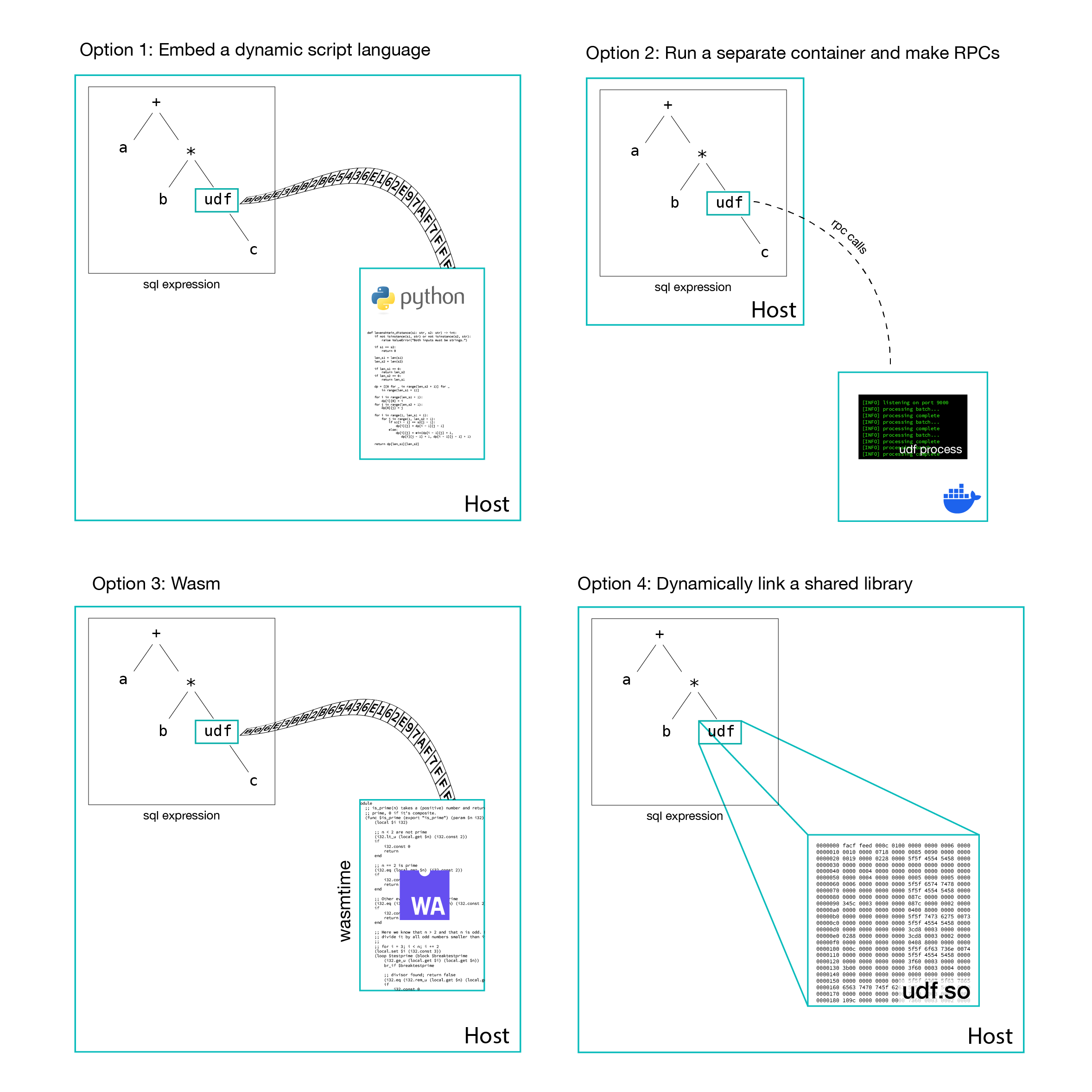
There are a number of options for how one can invoke user code at runtime:
1. Embed a scripting language
languages like Python and JavaScript can be run dynamically without any pre-compilation, and ir interpreter could be hosted within the engine. Arroyo uses the cross-language-compatible Apache Arrow data format, so there needn’t be any serialization across the language barrier. However, there would still be a significant performance cost compared to our native Rust functions, and this would break backwards-compatibility with existing Rust UDFs.
This approach is common in applications where plugin performance isn’t critical, for example GUI plugins in creative applications where the plugin code is orchestrating rather than processing itself.
2. Run UDFs are a separate process, with RPC calls
Each UDF could be compiled as a separate service (or all UDFs for a pipeline could be compiled together into a single service) that runs as a sidecar to the main worker process. When the UDF is invoked during expression evaluation the engine would make an RPC call with the input data and get the return value back.
There are several advantages to this approach, which isolates user-written code from the engine process. It’s able to crash independently, and have its own resource limits for CPU and memory. And by running it in a separate, locked-down container or VM, we could even run potentially malicious UDFs in a cloud environment without concern that they could compromise shared infrastructure.
The downside again is performance. Even with batching, the overhead of an RPC call is much higher than a pure function call, and requires serialization and deserialization of data. It also adds to the deployment complexity, as this would be other services that need to be managed.
The RPC approach to plugins is often used when the host seeks to isolate itself from potentially buggy plugin code and to easily support multiple languages; for example text editors today use RPCs via the Language Server Protocol and in the data space Apache Beam uses RPCs to support cross-language UDFs.
3. Compile to Wasm
Now we’re cooking with gas. Web assembly—Wasm—is the hottest thing in cross-language execution. UDF code written in a language like Rust can be compiled into a Wasm binary, which can then be dynamically executed by a Wasm runtime like Wasmtime or Wasmer.
Wasm is a genuinely exciting technology; it’s an assembly-like language that is portable across languages, operating systems, and CPU architectures. In theory this means that a host doesn’t need to know or care what the original language of the plugin. In addition to the portability, Wasm runtimes are also designed to be sandboxes, in theory allowing untrusted user code to run without compromising their host. Finally, Wasm supports fine-grained resource management; a host can limit how much CPU and memory a plugin can use.
All of these are great properties for a UDF system, and I have no doubt that Wasm will be part of how engines solve this problem in the future. Today, though, there are some limitations.
First, performance. Wasm code is still slower than native (anywhere from 1.5x-3x depending on the task). Beyond the runtime cost, sending data to a Wasm function generally requires copying it into the Wasm memory, which can be substantial overhead for simpler operations.
Second, compatibility. Not all Rust code can easily be compiled to Wasm. For example, anything that requires linking to a C library will not work out of the box. Many other features of Rust (threads, syscalls, networking, etc.) are not directly supported. The situation for other languages is much worse. For dynamic, GC’d languages like Python the best option today is to compile the interpreter itself to Wasm, but this means that most libraries that rely on C extensions (like numpy, scipy, pandas) won’t work without special support.
In short, today plugin authors need to be very familiar with Wasm and its limitations in order to successfully build more complex UDFs.
4. Shared libraries
Shared objects (.dlls on Windows, .so files on Linux, .dylibs on MacOS) are a common way to distribute library code. They can be dynamically linked, meaning that the application code needs only to know the interface at compile time, but not the actual code. They can even be dynamically loaded after program startup.
Dynamic linking is also a traditional way to implement plugin systems. For example, Digital Audio Workstations like Logic Pro and Ableton support shared-object plugins to implement effects and instruments, with standards like VST and AU. Other creative applications like photo editors and 3d graphics tools have similarly offered plugin interfaces via shared libraries.
In many ways, this is an obvious choice: functions from shared libraries have almost the same performance as native functions2, and we would have complete compatibility for the wide universe of crates.
Unfortunately, dynamic linking is quite challenging in Rust. The language lacks a stable ABI (Application Binary Interface), which is the contract between function caller and callees about how variables will be laid out in memory, how structures are laid out, and other low-level details needed to correctly call out to foreign code. This means that shared libraries need to have been compiled with the exactly same compiler version (and possibly compiler options) as the host binary in order to be loadable.
But there is a workaround: use the C ABI. Unlike Rust, C does have a stable ABI on every major OS and processor architecture. So if we can constrain our plugin interface to only use C-compatible data structures and functions we can safely link against plugins compiled by any Rust compiler. Even better: as the C ABI is the lingua franca in the systems world, many other languages are able to emit it, opening the door to supporting UDFs in a variety of compiled languages.
This is the path we took for UDFs in Arroyo.
Implementing a C interface
So how do you go about building a C ABI in Rust? There are a number of limitations and rules to follow to safely call functions over a C FFI boundary.
Designing our types
The first thing we need to think about is data—the stuff getting passed between the host and plugin code. Rust gives us many powerful tools for modeling data, including structs, enums, tuples, various data structures… and we’re going to have to give nearly all of them up. To correctly and reliably pass data over a C FFI boundary, we have to follow some very limiting rules.
Rule 1: repr(C)
Our first issue is that Rust’s data layout is ABI dependent, and can (and does) change with different versions of the compiler. So we get to the first rule of building a C interface: all data needs to be #[repr(C)].
At this point I’d like to introduce an extremely helpful resource for anyone straying from the cosy, warm cottage of safe Rust and out into the deep dark night of unsafe: the Rustonomicon. It helpfully disclaims responsibility for potentially “UNLEASHING INDESCRIBABLE HORRORS THAT SHATTER YOUR PSYCHE AND SET YOUR MIND ADRIFT IN THE UNKNOWABLY INFINITE COSMOS.”
With that warning in mind, its section on data layout and repr can be found here.
Repr annotations allow developers to specify specific data layouts for structs and enums, where the default is “whatever the Rust compiler wants to do and thinks is efficient.” There are several support layouts, but the rules for repr(C) is pretty simple: just do whatever C does.

Staring too long into the abyss of unsafe Rust can have interesting consequences
To use alternative representations, we can create a data type (struct or enum) and annotate it like this:
#[repr(C)]
struct MyData {
a: f32,
b: i64,
c: u8
}This struct demonstrates why #[repr(C)] is important. Compiling this code using the nightly-only rustc option -Zprint-type-sizes we can see that we end up with completely different layouts for #[repr(Rust)] and #[repr(C)]:
// #[repr(Rust)]
print-type-size type: `MyData`: 16 bytes, alignment: 8 bytes
print-type-size field `.b`: 8 bytes
print-type-size field `.a`: 4 bytes
print-type-size field `.c`: 1 bytes
// #[repr(C)]
print-type-size type: `MyData`: 24 bytes, alignment: 8 bytes
print-type-size field `.a`: 4 bytes
print-type-size padding: 4 bytes
print-type-size field `.b`: 8 bytes, alignment: 8 bytes
print-type-size field `.c`: 1 bytes
print-type-size end padding: 7 bytesIn fact, the Rust representation is much more efficient, taking up only 16 bytes instead of 24 bytes for the C representation. This is because Rust is free to reorder the fields to reduce the number of padding bytes needed to align to 8 bytes. C on the other hand will always lay out fields in order with predictable padding rules, which we see in the second version.
That example struct stuck to simple, primitive data types. And that leads into rule number 2:
Rule 2: all data must be FFI safe
While #[repr(C)] allows us to create structs and enums that can be passed across an FFI boundary, that property is not recursive—that is, it controls the layout of fields within the struct, but doesn’t affect the representation of the fields themselves.
In fact, we are quite limited in what data types are FFI safe. This is not a well documented area of Rust, but an incomplete list of FFI safe types includes:
- Primitive Types:
u8,u16,u32,u64,i8,i16,i32,i64,usize,isize,f32,f64, andbool. - Pointers: Raw pointers
const Tandmut T; safe wrappers for nullable pointers likeOption<NonNull<T>> - C-compatible Enums: Enums with explicitly defined
repr(C). - C-compatible Structs: Structs with
repr(C)and containing only FFI-safe types. - Slices:
[T],const [T], andmut [T]when length is provided separately.
So no passing String, Vec, HashMap, or random data types from your favorite Rust crate. However, we do have tools for passing some useful types of data with a little bit of transformation. The std::ffi package includes CString and CStr which are owned and borrowed null-terminated C-style strings. Similarly, we can pass Vec by converting it into a raw pointer + length + capacity and then back again.
Exporting functions
Once we’ve decided on our data types, we’re ready to design our actual API, by exporting C-compatible functions. A C FFI function is a bare Rust function with
- A
#[no_mangle]annotation, which tells rustc to name the symbol as exactly the function name, instead of rewriting it (or “mangling”) to ensure uniqueness and include useful metadata - The
extern "C"keyword, which tells rustc to export the function for external use using the C ABI - All arguments and a return type that are FFI safe3, as described above
So putting that together, we can export a C FFI function with the following definition
#[no_mangle]
extern "C" fn add(a: u32, b: u32) -> u32 {
a + b
}Within the plugin code, we can use almost any Rust construct or features, so long as nothing leaks into the type signature.
The biggest exception is panic. Rust’s default panicking behavior is unwinding, which means we travel up the call stack until we hit either a catch_unwind call (which stops the unwinding) or the top stack frame for the thread, in which case the thread exits. But this is a Rust-specific feature, part of the unstable Rust ABI. Unwinding can’t cross a C FFI boundary without risking undefined behavior.

And important rule for hitchhiking across the galaxy and crossing FFI boundaries
There are two ways to handle this: either we need to compile our plugin code with panic = 'abort' (which causes the process to terminate on panic) or we need to ensure that the plugin cannot panic. But even if we can ensure our own code is panic-free4, how can we make sure our plugin-writing-users do the same?
One answer is to use a plugin interface with a top-level catch_unwind call that converts panics into an Error enum across the FFI boundary.
Compiling our plugin
Our plugin will be a library crate that’s built as a shared object, in a binary format that depends on our operating system (.so on Linux, .dll on Windows, .dylib on MacOS).
By default, Rust compiles libraries as an rlib artifact, which is a Rust-specific static library format. To tell it to instead build a dynamic system library that can be linked by other languages, we’ll use the cdylib type. This can be specified in a Cargo.toml by setting the lib.crate-type option, like this:
[package]
name = "my-plugin"
version = "1.0.0"
edition = "2021"
[lib]
crate-type = ["cdylib"]Calling FFI functions
There are two different ways we might link and call plugin code across an FFI: at program start time, or dynamically as the program is executing. In either case, we’ll use the extern keyword again but without a function body in order to tell the host side what the function signature is.
If we know the name of the library at compile time, Rust provides built-in support for loading system libraries using the [link] annotation. It looks like this:
#[link(name = "my_plugin")]
extern "C" {
fn add(a: u32, b: u32) -> u32;
}
fn main() {
unsafe { add(1, 5) };
}Rust will look for a shared library with the name my_plugin (for example, on Linux it will look for /usr/lib/my_plugin.so, /usr/local/lib/my_plugin.so, etc.) and attempt to link it at program start time, and will fail if it can’t find the library. The function can be called like any other (unsafe) Rust function5.
But for a plugin system, having to know the name of the library at compile time (and ensuring that it’s installed in a system location) is somewhat limiting. Instead, we can turn to dynamic loading.
The interfaces for dynamic library loading are OS-specific, but there are several crates that can handle the cross-platform boilerplate for us. The two most popular are libloading and dlopen2. For Arroyo we decided to use dlopen2 which has a nicer interface and stronger guarantees around thread safety.
In dlopen2, we can define structs for each of our plugin interfaces. They look like this:
#[derive(WrapperApi)]
pub struct PluginInterface {
add: extern "C" fn(a: u32, b: u32) -> u32,
}A plugin can be loaded and called like this:
let container: Container<PluginInterface> = unsafe {
Container::load(dylib_path).unwrap()
};
unsafe { container.add(1, 3) }Putting it all together
So that was a lot of theory. Let’s put it into practice with a complete example! We’ll be working off a (very simplified) example plugin system found in this repo. Clone it locally to try this out yourself.
The code is divided into two parts: the plugin, which compiles to a shared object, and the host, which loads the plugin. (In a real system, you’d likely want a few more components, including a common library to share definitions between the plugin and host, and a macro to do code generation, but we’re keeping this relatively simple.)
Designing the interface
Before we can start writing code, we need to decide on the contract between the plugin and the host. For this example, we’ll adopt a flexible contract that supports a variable number of arguments of various common data types, as would be needed for a UDF system.
The plugin interface has two methods:
extern "C" fn plugin_metadata() -> PluginMetadata,
extern "C" fn plugin_entrypoint(
args: *const PluginValue, args_len: usize) -> PluginResultThe metadata function is called by the host to determine the number and types of the arguments the plugin expects, and the type of the data it returns, while the entrypoint function is called to actually execute the plugin’s logic.
As discussed in detail above, all of our data types need to be FFI-safe. For example, the PluginMetadata type looks like this:
#[repr(C)]
#[derive(Copy, Clone)]
pub enum PluginType {
Bool,
Int,
UInt,
Double,
String,
}
#[repr(C)]
pub struct PluginMetadata {
// should have a static lifetime
pub name: *const i8,
pub arg_types: *const PluginType,
pub arg_types_len: usize,
pub return_type: PluginType,
}Note that instead of of passing a String for the name, we pass a *const i8, which represents a null-terminated C-style string. Instead of a Vec<PluginType> for the args, we pass a pointer to some memory and a length.
For the entrypoint function, we’ll need to pass our actual data to the plugin. That relies on an array of values of the type PluginValue:
#[repr(C)]
pub enum PluginValue {
Bool(bool),
Int(i64),
UInt(u64),
Double(f64),
// All strings are owned by the host
String(*const i8),
}For primitives, we can use them as-is as all Rust primitives are FFI-safe. However, strings again need special attention. We have two typical options for passing strings: we can pass Rust-style strings (with an array of chars and a length) or C-styles strings (whose end is determined by a null byte). While the former are much safer and generally preferred in modern APIs, for C interfaces the latter is more common as it’s more easily supported by languages with a C FFI.
Beyond the format of the data, we also need to consider ownership6. Once memory is allocated, exactly one part of our code (in this case, one side of the host/plugin divide) needs to own that memory. PluginValues are both created by the host (to provide data) and by the plugin (to return its result), but to simplify the memory management we have documented that in both cases the host owns the memory and is responsible for freeing it. This does mean the plugin code needs to be careful never to create an owned-object from the memory (in this case, a CString) which would free it on drop.
Finally, we have our return type, which is just an FFI-safe Result type with a CString error message:
#[repr(C)]
pub enum PluginResult {
Ok(PluginValue),
// Null-terminated c-string; he host is responsible for
// freeing this value
Err(*mut i8),
}Now that we have our common interface, let’s see how they’re used. We’ll start with the plugin.
We’re using two different types of raw pointers here: *mut and *const. Why is that? What’s the difference? In the context of FFI, the answer is: not much. The choice of mut vs const doesn’t affect the generated code, and you can freely cast between them.
However, they are useful for documenting intent and ownership across an FFI boundary. Using *const tells the calling code that they shouldn’t modify the data behind the pointer, and probably shouldn’t free it, while *mut indicates that it’s ok to modify the data and can also communicate ownership.
We’re playing a bit fast-and-loose here, because we’re using a single data type (PluginValue) for both our arguments—which the host creates and owns—and our return value, which the plugin creates but transfers to the host, so we opt for *const to tell the plugin not to modify or free its arguments. However, on the host side we then have to cast it to *mut so that we can take ownership.
The plugin
We’re going to implement a simple plugin that takes in two arguments, a string and a number, and will return the string repeated that number of times: f("cool", 3) ⇒ "coolcoolcool" .
The plugin is responsible for building a shared library, so we need to tell Cargo that’s what we want. We do that by specifying the crate type as cdylib, a C-compatible dynamic library. Our Cargo.toml looks like this:
[package]
name = "plugin"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib"]Next is our src/lib.rs file. This will contain implementations of the plugin interface documented above.
The first function we need to implement is plugin_metadata(), which is pretty straightforward, telling the host about our arguments and our return type:
#[no_mangle]
pub extern "C" fn plugin_metadata() -> PluginMetadata {
PluginMetadata {
name: "repeat\0".as_ptr() as *const i8,
arg_types: [PluginType::String, PluginType::UInt].as_ptr(),
arg_types_len: 2,
return_type: PluginType::String,
}
}Next we’ll implement our plugin’s unique logic, in this case repeating a string N times. I find it easiest to separate this out from the boilerplate that’s involved in converting to and from FFI types, so that when we’re developing the logic we can stay in safe, normal Rust land.
fn repeat_impl(input: &str, count: u64) -> String {
input.repeat(count as usize)
}Nice and simple. Unfortunately, we still need the complex code to bridge the FFI and Rust worlds. For this example, it looks like this:
#[no_mangle]
pub extern "C" fn plugin_entrypoint(args: *const PluginValue,
args_len: usize) -> PluginResult {
// first we need to check if the arguments are valid
if args_len != 2 {
return plugin_error("args_len should be 2");
}
let PluginValue::String(string) = (unsafe { &*args.offset(0) }) else {
return plugin_error("arg0 is invalid; expected String");
};
let PluginValue::UInt(count) = (unsafe { &*args.offset(1) }) else {
return plugin_error("arg1 is invalid; expected UInt");
};
let string = match unsafe { CStr::from_ptr(*string) }.to_str() {
Ok(value) => value,
Err(_) => {
return plugin_error("arg0 is invalid; expected valid UTF-8 string");
}
};
// then we can call our logic with the converted arguments and re-wrap them
// in our Result type, catching any panics that might occur so that they
// don't cross the FFI boundary
match catch_unwind(|| repeat_impl(string, *count)) {
Ok(value) => PluginResult::Ok(
PluginValue::String(CString::new(value).unwrap().into_raw())),
Err(_) => plugin_error("function panicked"),
}
}Making your users write all of this unsafe boilerplate for every plugin isn’t great UX, so you may want to use a macro or just wrapper code (if you don’t need to support multiple types). You can see the macro for the Arroyo plugin system here.
The host

(not this one)
The host is a normal Rust application, created with cargo new. It has one dependency, dlopen2, which we’ll use to dynamically load our plugin:
[dependencies]
dlopen2 = { version = "0.7.0", features = ["derive"] }The meat is in src/main.rs, which builds our binary. We need to repeat the definitions (or include them from a common library), but we’ll also include one more, an owned version of PluginValue:
pub enum OwnedPluginValue {
Bool(bool),
Int(i64),
UInt(u64),
Double(f64),
String(CString),
}
impl PluginValue {
pub fn to_owned(self) -> OwnedPluginValue {
match self {
PluginValue::Bool(b) => OwnedPluginValue::Bool(b),
PluginValue::Int(i) => OwnedPluginValue::Int(i),
PluginValue::UInt(u) => OwnedPluginValue::UInt(u),
PluginValue::Double(d) => OwnedPluginValue::Double(d),
PluginValue::String(s) => {
OwnedPluginValue::String(
unsafe { CString::from_raw(s as *mut i8) })
}
}
}
}This owned struct will allow us to ensure that values returned from the plugin (and the arguments we send it) are eventually freed.
Next, we’ll define the plugin interface using dlopen2’s WrapperApi macro:
#[derive(WrapperApi)]
struct PluginApi {
plugin_metadata: unsafe extern "C" fn() -> PluginMetadata,
plugin_entrypoint:
unsafe extern "C" fn(args: *const PluginValue, args_len: usize)
-> PluginResult,
}This let’s us conveniently bundle up all of the plugin functions into a struct which we can store and pass around our application.
Now we’re ready to load the plugin and call it. I’ll spare you the details of CLI argument processing (which you can see in the full example file). Here’s the meat of it:
// load the plugin via the dlopen2's Container API
let container: Container<PluginApi> =
unsafe { Container::load(&args[1]) }.expect("Could not load plugin");
// get the metadata, which will tell us which arguments to expect
let metadata: PluginMetadata = unsafe { container.plugin_metadata() };
// read the arguments from the command line
let mut call_args: Vec<PluginValue> = vec![];
for (i, arg) in args[2..].iter().enumerate() {
match unsafe { *metadata.arg_types.add(i) } {
PluginType::Bool => {
call_args.push(PluginValue::Bool(
arg.parse().expect("Invalid bool")))
}
...
}
}
// call the plugin function
let result = unsafe {
container.plugin_entrypoint(call_args.as_ptr(), call_args.len())
};
// take ownership and drop the arguments to free their memory
drop(call_args.into_iter().map(|t| t.to_owned()));
// print out the result or error to the user
match result {
PluginResult::Ok(value) => {
println!("Plugin returned: {}", value.to_owned());
}
PluginResult::Err(err) => {
eprintln!("{}", unsafe { CString::from_raw(err) }.to_string_lossy());
std::process::exit(1);
}
}Let’s plug in some stuff!!!
Here we are. After more than 5000 words, we’re going to actually dynamically load some Rust code.

uhh… not like that
If you want to follow along, check out the example repo
$ git clone https://github.com/mwylde/rust-plugin-tutorial.gitThen we’re going to build both the plugin and host
$ cd rust-plugin-tutorial/plugin && cargo build
$ cd ../host && cargo buildNow we should have a dynamic library in plugin/target/debug and a host binary in host/target/debug. The dynamic library will be named something like “libplugin.dylib,” “libplugin.so,” or “libplugin.dll” depending on your operating system. Note which it is, then invoke the host like this:
$ host/target/debug/host plugin/target/debug/libplugin.dylib cool 3
Loaded plugin repeat
Plugin returned: coolcoolcoolIf all went well, you should see the output from your plugin code (and no pesky segfaults).
Wrapping up
So that’s the background for how we built our plugin system, and how you can build your own.
Recapping a bit:
- We defined our data types as enums and structs of FFI-safe types
- We defined a plugin interface, as
#[no_mangle] extern "C"functions consuming and returning those data types - We used dlopen2 to load and call our plugin interface from the host
In part 2 of this series, we’ll cover how this works in a real, production plugin system, including support for async functions. (If you’re impatient, all of the code can be found here.)
Questions? Concerns? Issues? Abuse? You can reach me on the Arroyo Discord or at micah@arroyo.systems.
Footnotes
This is a bit simplified; the actual compilation has to take into account SQL’s complex nullability rules. See a more complete example here. ↩
In practice dynamically-linked functions can run a bit slower as they can’t be inlined or take advantage of link-time or profile-guided optimizations. ↩
The Rust compiler will helpfully warn you if you use a non-FFI-safe type in an
externfunction ↩Which… of course we all do ↩
All FFI functions are inherently unsafe, as Rust can’t guarantee anything on the other side of the FFI boundary. For that reason, It’s typical to write safe wrappers around FFI functions that ensure the invariants expected by the library are upheld. ↩
Rust-haters complain about the lifetime and borrowchecker systems but those issues don’t go away just because your compiler doesn’t yell at you about it. In C APIs you always need to know who owns a piece of memory and who’s responsible for freeing it. But without language support you just have to document it and hope for the best. ↩