

At Arroyo we’re building a state-of-the-art stream processing engine in order to bring real-time data to everyone. Today, the default tool for stream processing is Apache Flink. But having built Flink-based streaming platforms at Splunk and Lyft, we decided early that Flink’s limitations made it the wrong foundation for building a reliable, efficient platform.
Starting from scratch on a new, Rust-based streaming engine is a daunting task, but it gives us the opportunity to greatly improve the streaming user experience. Part of that UX is enabling our users to write whatever queries they want without deep knowledge of the performance characteristics of the engine.
That requires great baseline performance, but also that seemingly reasonable queries don’t fall off a performance cliff. In this post, I’m going to talk about one example of how our architecture unlocks a class of query patterns that exhibit pathological behavior in Flink.
What’s a sliding window?
A sliding window (or hop window) is a common structure in stream processing, found in Flink, Cloud Dataflow, KSql, and Spark Streaming. It is defined by two time durations, a width for each window and a slide that designates the time between the start of consecutive windows. Typically the slide is less than the window. A sliding window can be used to provide a view of data over some lookback time (the width), updated with some frequency (the slide).
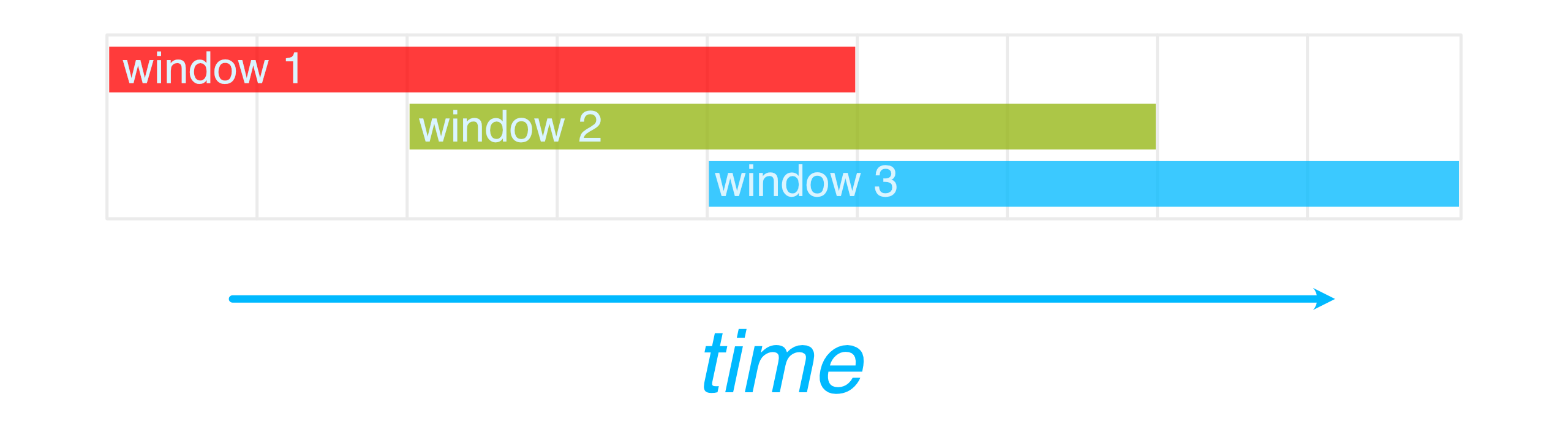
An example sliding window with width=5 and slide=2
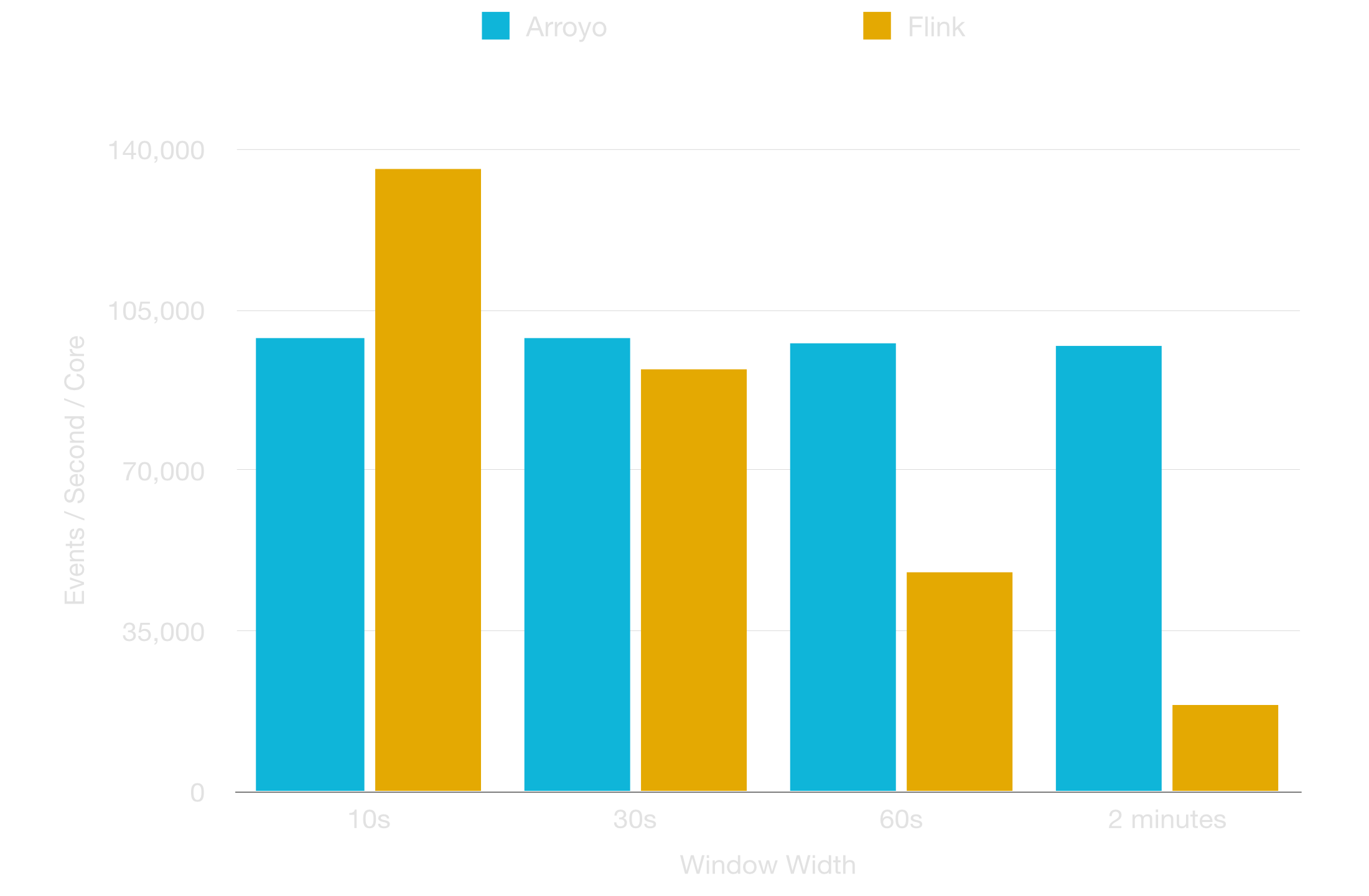
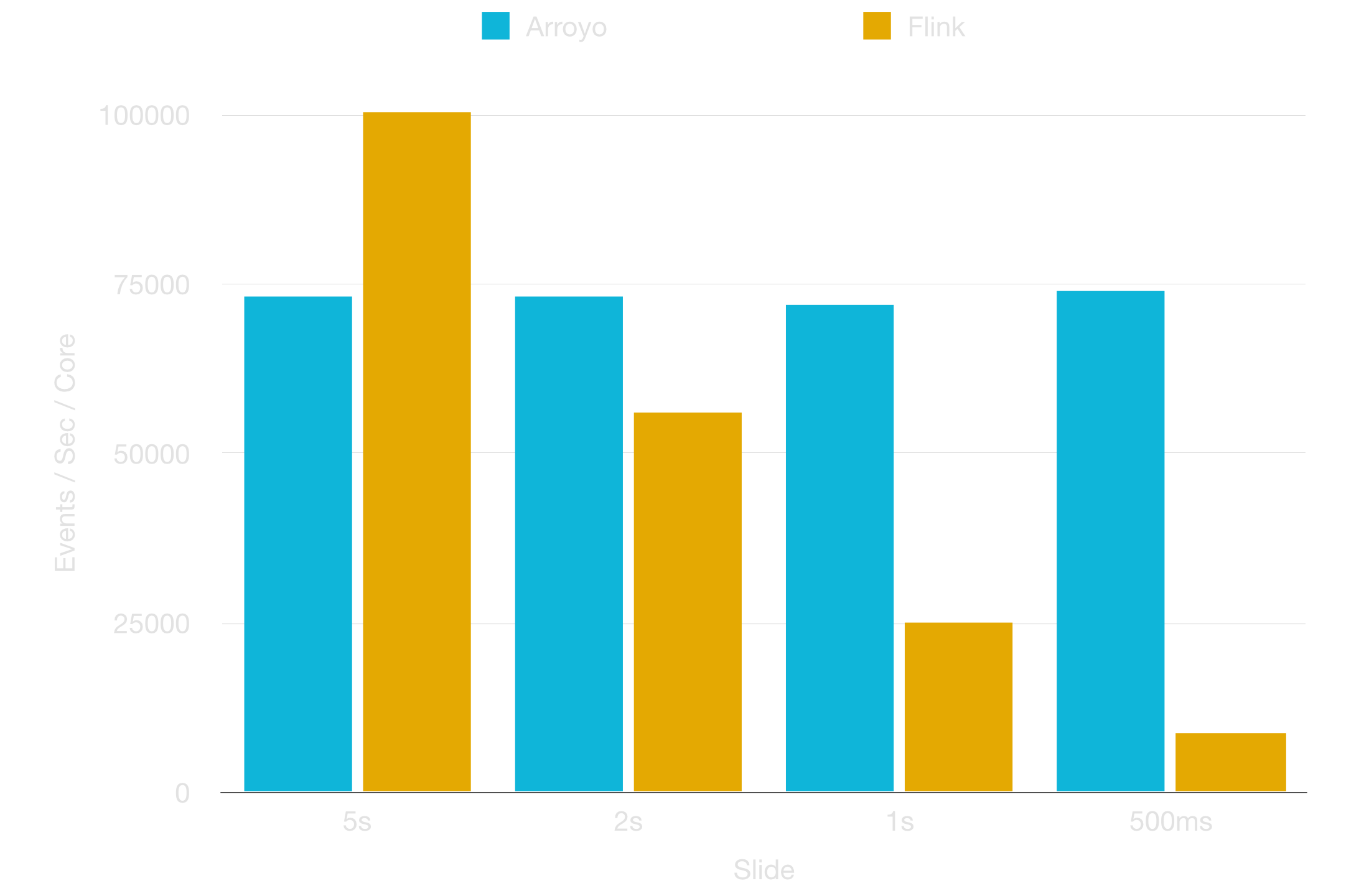
In Flink, throughput shows a drastic drop-off as you decrease the slide, while Arroyo is able to keep nearly constant throughput across smaller slides, and at constant slides across larger windows.
2 second slide at 500k events per second, varied width
60 second width for 3 minutes over 200K EPS, varied slide
How Arroyo solves short slides
Our sliding window algorithms are designed to work efficiently even when the width is much bigger than the slide. This is done by storing the data for each key in a structure that allows for incremental modifications as time advances. For example, to count the number bids with a given auction_id across a sliding window, the SQL would look like
SELECT auction_id,
hop(interval '2 seconds', interval '2 minutes') as window,
count(*) as bids
FROM bids
GROUP BY 1,2Arroyo uses a data type called WindowState to efficiently compute consecutive sliding windows. On receipt of a record, window_state.add_event_to_bin(bin_time) is called to update the account for the relevant bin, and when it is time to emit a new window, window_state.tick(next_bin) updates the state and returns the count for the current window.
struct WindowState {
width: Duration,
prior_window_count: i64,
bin_counts: BTreeMap<SystemTime, i64>,
}
impl WindowState {
fn add_event_to_bucket(&mut self, bin_start: SystemTime) {
self.bin_counts
.entry(bin_start)
.and_modify(|prior_value| {
prior_value.add(1);
})
.or_insert(1);
}
fn tick(&mut self, next_bin: SystemTime) -> i64 {
let leaving_bin = next_bin - self.width;
self.prior_window_count -= self.bin_counts
.remove(&leaving_bin).unwrap_or_default();
self.prior_window_count += self.bin_counts
.get(&next_bin)
.map(|val| *val)
.unwrap_or_default();
self.prior_window_count
}
}This approach is efficient as the slide shortens. In particular, you only pay a memory penalty as the number of non-empty bins will increase. If your query is doing additional processing, such as returning the top N values within the window it becomes more challenging to structure the operator to reuse data from the previous window.
How does Flink handle sliding windows?
Flink’s sliding window implementation works like other Flink windows. It calculates all the windows that a record belongs to and performs the aggregation within each window. Let’s take for example a count aggregation on the width=5, slide=2 case shown above. An event at t=4 would belong to window1, window2, and window3. Flink will load the current count of the existing windows (w1 and w2), increment them, initialize a new w3 with count 1, then write that all back to stack.
This is fine when the number of windows is small. But as the slide shortens, the number of windows each record belongs to increases. For each event, width / slide windows need to be updated. For a 1 hour / 5 second window that’s 720 updates! Once the width is much more than 10x the slide, this inefficiency dominates, exploding the computation cost.
Why hasn’t Flink solved this?
The Flink community has known that sliding windows could be done more efficiently since 2016. A detailed proposal for more efficient sliding windows can be found in FLINK-7001 and the linked papers and design documents. Arroyo’s algorithms leverage similar insights and constructs to achieve performance that is unaffected by small slides or large windows. Despite this, no progress has been made. There are a few reasons for this:
Overly General Windowing APIs
Flink’s Java APIs allow users to specify the fine-grained behavior of windows, including triggers, evictors, and aggregators. It also materializes every future window and schedules a trigger for it. This is fine for most windowing strategies, as they tend to only have one window per event. However, this means it doesn’t take advantage of the particular semantics of sliding windows.
SQL against a developer API
Flink SQL is implemented against the same public APIs used by programmers creating Flink pipelines in Java. However, Java developers are given direct access to the low-level primitives of Flink for precise control over the performance and behavior of their pipelines. As a result, the internal architecture becomes part of the public API, making fundamental changes nearly impossible. With Arroyo, the public interface is simply SQL, giving us the freedom to make rapid changes to improve performance without affecting users.
Open Source Inertia
As big open source projects mature they also tend to harden around their initial implementations and user base. Any breaking API change or performance degradation will face an incredibly high barrier to entry. Flink has also lacked a strong corporate sponsor for many years, which makes drastic changes to the architecture incredibly hard to execute.
SQL-First real-time processing
I learned how to code writing and optimizing Hadoop Map-Reduce jobs, and for many years taught the tutorial given to every new engineer. However with each year, it made less and less sense to train engineers in this difficult technology. Dataframe and SQL-based query engines are now dominant in data processing. They pair widely adopted declarative APIs with powerful backends. Arroyo provides an execution system that is optimized specifically for real-time SQL, where users just worry about the business logic and we make sure it is maximally efficient.