

The Arroyo team is pleased to announce the release of Arroyo 0.9.0. This release includes a support for much more powerful async UDFs, support for joining update tables, a new Confluent Cloud connector, control over deserialization errors, and more.
Arroyo is an open-source stream processing engine, enabling everyone to build correct, reliable, and scalable real-time data pipelines using SQL.
For this release, we are thrilled to welcome two new contributors to the Arroyo project:
- @tqwewe made their first contribution in #456
- @breezykermo made their first contribution in #476
Thanks to all our contributors for this release:
Want to try out the new features? You can start a local instance of Arroyo 0.9 in Docker with:
$ docker run -p 8000:8000 ghcr.io/arroyosystems/arroyo-single:0.9.0Read on for more, and check out our docs for full details on existing and new features.
What’s next
Arroyo 0.10, coming in mid February, will be our largest release yet. We’re not quite ready to share all the details, but stay tuned here and on Discord for more details in the coming weeks.
Table of Contents
- Async UDFs
- Joining Update tables
- Bad Data handling
- Environment variable substitution
- Confluent Cloud connector
- Connection Profile UI
- Fixes
- Improvements
Async UDFs
User-defined functions (UDFs) and user-defined aggregate functions (UDAFs) allow you to extend Arroyo with custom logic. New in Arroyo 0.9 is support for what we call async UDFs.
Existing (sync) UDFs are expected to implement simple, computational logic. Common use cases include parsing custom formats, implementing functions that are not natively supported, or implementing custom business logic that would be difficult to express in SQL. Because they are run synchronously with processing, if they take too long to run they can block the entire pipeline.
This isn’t a hypothetical concern. A UDF that takes 10ms to run will be limited to processing just 100 events per second per subtask!
And there are many use cases where you want to run logic that is not a simple, stateless computation. You may need to do point lookups in a database to enrich events, make an API call to another service, or even perform inference against an AI model.
Async UDFs allow you to do all of these things, without blocking the pipeline. Async UDFs are defined as a Rust async fn, supporting non-blocking IO. Then within the Arroyo runtime, many instances of the UDF can be run in parallel, with a configurable concurrency limit.
What does this look like? Let’s take an example of a UDF that enriches web events with GeoIP data by calling a GeoIP service. First, we define the UDF:
/*
[dependencies]
reqwest = { version = "0.11.23", features = ["json"] }
serde_json = "1"
[udfs]
async_max_concurrency = 1000
*/
pub async fn get_city(ip: String) -> Option<String> {
let body: serde_json::Value =
reqwest::get(
format!("http://geoip-service:8000/{ip}"))
.await
.ok()?
.json()
.await
.ok()?;
body.pointer("/names/en").and_then(|t|
t.as_str()
).map(|t| t.to_string())
}Then we can use this UDF in a query, for example this one that finds the most common cities in the last 15 minutes:
create view cities as
select get_city(logs.ip) as city
from logs;
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER (
PARTITION BY window
ORDER BY count DESC) as row_num
FROM (SELECT count(*) as count,
city,
hop(interval '5 seconds', interval '15 minutes') as window
FROM cities
WHERE city IS NOT NULL
group by city, window)) WHERE row_num <= 5;Async UDFs support several configuration options that control their behavior, including the maximum number of concurrent requests, timeouts, and whether event order should be preserved.
They also support defining a Context struct which is passed in to each invocation of the UDF. This allows you to do setup for expensive operations (like setting up a Database connection pool) just once, and share the result with all invocations.
For example, we can create a client for Postgres like this:
pub struct Context {
client: RwLock<Option<Client>>,
}
impl Context {
pub fn new() -> Self {
Self {
client: RwLock::new(None),
}
}
}
#[async_trait]
impl arroyo_types::UdfContext for Context {
async fn init(&self) {
let conn_str = "host=localhost user=dbuser password=dbpassword dbname=my_db";
let (client, connection) = tokio_postgres::connect(conn_str, NoTls).await.unwrap();
let mut c = self.client.write().await;
*c = Some(client);
tokio::spawn(async move {
if let Err(e) = connection.await {
println!("connection error: {}", e);
}
});
}
}See the docs for full details.
- Add Async UDFs by @jbeisen in #483
- Enable user-defined context structs for async UDFs by @jbeisen in #487
Joining Update tables
Arroyo has two semantics for streaming SQL, one based on event-time watermarks and another that we call “Update Tables,” which allow for incremental computation of most analytical SQL constructs. However, previously there was a restriction on joins, which were only supported for the watermark semantic.
Now that restriction is gone, and update tables can be joined. Hurray!
For example, this query will count the number of page views by user, and when a transaction comes in joins that accumulated count:
CREATE VIEW page_view_counts as
SELECT count(*) as count, user_id as user_id
FROM page_views
GROUP BY user_id;
SELECT T.user_id, amount, P.count as page_views
FROM transactions T
LEFT JOIN page_view_counts P on T.user_id = P.user_id;- Support joining updating data by @jbeisen in #420
- Just retract the final row of an outer join, rather than (None, None) by @jacksonrnewhouse in #490
Bad Data handling
It happens to the best of us. You’ve carefully built out your data architecture, perform rigorous code reviews, and diligently monitor your rollouts.
And yet it happens—somehow, invalid data got into your Kafka topic. Now in Arroyo 0.9, you can now configure the source to drop bad data instead of causing a processing failure.
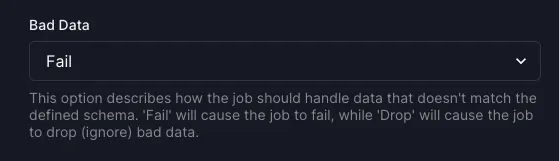
This behavior can be configured via the Web UI or with the bad_data option when creating a source in SQL. Two options are currently available:
fail(default, and behavior in Arroyo 0.8) causes the pipeline to restart when bad data is encountereddropcauses the data to be dropped, while logging an error message to the console and incrementing thearroyo_worker_deserialization_errorsmetricAdd control for deserialization error behavior by @jbeisen in #443
Add bad data option to create connection form by @jbeisen in #452
Environment variable substitution
Some connectors need to be configured with authentication details or other secret data. Today in Arroyo those secrets are stored in the configuration database (postgres), which is not very secure.
Now in Arroyo 0.9, we’re introducing environment-variable substitution for sensitive configuration fields:

This feature allows you to use double curly braces ({{ }}) to reference environment variables, which will get substituted in at run time. For example, if you have an environment variable called WEBHOOK_SECRET you can now include this as a header in a webhook sink like
Authentication: Basic {{ WEBHOOK_SECRET }}Env variable substitution can be used for both connections created via the Web UI and those created directly in SQL, like:
CREATE TABLE slack (
value TEXT
) WITH (
connector = 'webhook',
endpoint = 'https://hooks.slack.com/services/{{ SLACK_KEY }}',
method = 'POST',
headers = 'Content-Type:application/json',
format = 'json'
);Confluent Cloud connector
Confluent is the company founded by the creators of Apache Kafka. They provide a cloud-native distribution of Kafka and serverless Kafka platform. While Arroyo has always supported reading and writing from Kafka, with Arroyo 0.9 we’re making it even easier to integrate with your Confluent Cloud topics with the new Confluent Cloud connector.
See the complete integration guide to get started.
Connection Profile UI
Connection Profiles encapsulate common configuration that is shared across multiple connection tables. For example, a single Kafka cluster may have many topics that you would like to consumer or produce to from Arroyo.
We’ve upgraded the process of creating and managing these profiles. It’s now possible to view and delete existing connection profiles, and the whole UI has gotten a little spiffier:
We’re also now validating that the profile is good (like ensuring we can talk to Kafka with the provided address and credentials), so you don’t discover you mistyped something at the end of the connection creation process.
- Redesign cluster profile UI and add validation by @mwylde in #454
- Add autocomplete when creating connections and Kafka topic autocomplete by @mwylde in #458
Fixes
- Fixes for schema registry and serialization by @mwylde in #447
- Reduce the panics in the parquet flusher, add retries to StorageProvider, send flusher failure by @jacksonrnewhouse in #445
- Make inter_event_delay nanos grain by @jacksonrnewhouse in #450
- Fix unset compression format panic by @jbeisen in #451
- Fix issues with enums in json form by @jbeisen in #453
- Incorrect redis url regex pattern by @tqwewe in #456
- Allow json schema fields that differ only by case by @mwylde in #465
- RawString schema’s value now submitted as non-nullable by @jacksonrnewhouse in #466
- Handle empty strings in JSON form by @jbeisen in #467
- Improve checkpointing robustness by @jacksonrnewhouse in #486
Improvements
- Validate schema and encoding issues when testing kafka connections by @mwylde in #460
- Remove old nodesource script that paused for 60 seconds during builds by @mwylde in #461
- Add PI & cot by @chenquan in #479
- Add to_hex by @chenquan in #478
- Communicate Kafka sink errors to console by @breezykermo in #476
- Allow restoring offsets from custom consumer group by @harshit2283 in #480
- Update mastodon url to our proxy in example by @mwylde in https://github.com/ArroyoSystems/arroyo/pull/491
- Support Redis username and password in RedisConnector #457 by @chenquan in https://github.com/ArroyoSystems/arroyo/pull/484
- Make webhook endpoint an env-var by @mwylde in https://github.com/ArroyoSystems/arroyo/pull/493
Full Changelog: https://github.com/ArroyoSystems/arroyo/compare/v0.8.1…v0.9.0