

The Arroyo team is excited to announce the release of Arroyo 0.7.0, the latest version of our open-source stream processing engine. This release includes a number of new features, including custom partitioning for the filesystem sink, message framing and unnest support, unions, state compaction, and more. Our focus on quality also continues, with a more sophisticated correctness test suite that can now test checkpointing and restoration.
And lastly, we’re rolling out some new branding with this release, including a new logo:
Read on for more, and check out our docs for full details on existing and new features.
Thanks to all our contributors for this release:
- @harshit2283 (new contributor!)
- @edmondop
- @haoxins
- @jbeisen
- @jacksonrnewhouse
- @mwylde
What’s next
With the 0.7 release out, we’re already working on the next one. Arroyo 0.8 is targeted for mid-November, and will include a number of new features, including support for Avro, Delta Lake integration, a FileSystem source, saved UDFs, and more. We’ve also been working on a new distributed state backend, which will allow Arroyo to scale to multi-TB state sizes while maintaining fast restarts and frequently checkpoints.
Anything you’d like to see? Let us know on Discord!
Now on to the details.
Table of Contents
- Custom partitioning for FileSystem sink
- Message Framing
- SQL unnest
- SQL union
- State compaction
- Arroyo CLI
- Console onboarding and example queries
- UDF checking in the console
- Array indexing
- Custom consumer groups for Kafka
- Restarting failed pipelines
- Improvements
- Fixes
Custom partitioning for FileSystem sink
Arroyo 0.5 added a high-performance, transactional filesystem sink which enables ingestion into data warehouses on S3. The initial version did not support custom partitioning of data, so records were written to a single file per subtask (with time and size-based rollovers).
In many cases, you will get better query performance if you partition your data by a field in your data (like an event type) or by time.
Arroyo 0.7 introduces support for field-based and time-based partitioning, allowing you to optimize your data layout according to your query patterns.
For example you can now create a table like this:
CREATE TABLE file_sink (
time TIMESTAMP,
event_type TEXT,
user_id TEXT,
count INT
) WITH (
connector = 'filesystem',
format = 'parquet',
path = 's3://arroyo-events/realtime',
rollover_seconds = '3600',
time_partition_pattern = 'year=%Y/month=%m/day=%d/hour=%H',
partition_fields = 'event_type'
);This will write data to a path like s3://arroyo-events/realtime/year=2023/month=10/day=19/hour=10/event_type=login.
See all of the available options in the docs.
- Implement event time and field based partitioning for filesystem sink by @jacksonrnewhouse in #352
Message Framing
Arroyo now supports defining a framing strategy for messages. This allows users to customize how messages read off of a source are split into records for processing, where previously there was always a one-to-one mapping. This is particularly useful for sources which do not have a built-in framing strategy, such as HTTP APIs.
As an example, Arroyo can now directly consume metrics from a prometheus-compatible application—without using Prometheus! Here’s a query that polls a prometheus endpoint (for a node exporter) and computes the CPU usage over a 1 minute sliding window:
create table raw_metrics (
value TEXT,
parsed TEXT generated always as (parse_prom(value))
) WITH (
connector = 'polling_http',
endpoint = 'http://localhost:9100/metrics',
format = 'raw_string',
framing = 'newline',
emit_behavior = 'changed',
poll_interval_ms = '1000'
);
create table metrics as
select extract_json_string(parsed, '$.name') as name,
cast(extract_json_string(parsed, '$.value') as float) as value,
get_first_json_object(parsed, '$.labels') as labels
from raw_metrics;
create table cpu as
select
extract_json_string(labels, '$.cpu') as cpu,
extract_json_string(labels, '$.mode') as mode,
value
from metrics
where name = 'node_cpu_seconds_total';
select sum(usage) from (
select rate(value) as usage, cpu, mode,
hop(interval '2 seconds', '60 seconds') as window
from cpu
where mode = 'user' or mode = 'system'
group by cpu, mode, window);This relies on the following UDFs:
fn parse_prom(s: String) -> Option<String>
/*
[dependencies]
regex = "1.10.2"
serde_json = "1.0"
*/
fn parse_prom(s: String) -> Option<String> {
let regex = regex::Regex::new(r"(?P<metric_name>\w+)\{(?P<labels>[^}]+)\}\s+(?P<metric_value>[\d.]+)").unwrap();
let label_regex = regex::Regex::new(r##"(?P<label>[^,]+)="(?P<value>[^"]+)""##).unwrap();
let captures = regex.captures(&s)?;
let name = captures.name("metric_name").unwrap().as_str();
let labels = captures.name("labels").unwrap().as_str();
let value = captures.name("metric_value").unwrap().as_str();
let labels: std::collections::HashMap<String, String> = label_regex.captures_iter(&labels)
.map(|capture| (
capture.name("label").unwrap().as_str().to_string(),
capture.name("value").unwrap().as_str().to_string()
))
.collect();
Some(serde_json::json!({
"name": name,
"labels": labels,
"value": value
}).to_string())
}fn rate(values: Vec<f32>) -> Option<f32>
fn rate(values: Vec<f32>) -> Option<f32> {
let start = values.first()?;
let end = values.last()?;
Some((end - start) / 60.0)
}Currently we support framing via newlines (specified as framing = 'newline' in SQL), although we plan to add support for other framing strategies in the future.
See the format docs for more.
SQL unnest
While framing allows you to split a single message into multiple records, this can only be applied at the source and for fairly simple framing rules. For other use cases you may want to do some computation or parsing that produces an array, and then unroll that array into multiple records.
This is what the new unnest operator does. It takes a column of type Array and produces a new record for each element in the array. This is often useful for dealing with JSON data, particularly from web APIs.
For example, the Github API doesn’t provide a websocket feed of events, but it does provide a REST API endpoint. We can use the polling_http connector along with unnest to turn that into a stream:
CREATE TABLE raw_events (
value TEXT
) WITH (
connector = 'polling_http',
endpoint = 'https://api.github.com/networks/arroyosystems/events',
poll_interval_ms = '5000',
emit_behavior = 'changed',
headers = 'User-Agent:arroyo/0.7',
format = 'json',
'json.unstructured' = 'true'
);
create table events AS (
select
extract_json_string(event, '$.id') as id,
extract_json_string(event, '$.type') as type,
extract_json_string(event, '$.actor.login') as login,
extract_json_string(event, '$.repo.name') as repo
FROM
(select unnest(extract_json(value, '$[*]'))
as event from raw_events));
select concat(type, ' from ', login, ' in ', repo) FROM (
select distinct(id), type, login, repo
from events
);- Implement unnest by @mwylde in #354
- Support multiple projections from a single unnest by @mwylde in #366
SQL union
The union operator allows you to combine the results of multiple queries into a single stream. This is often useful for combining similar data from multiple sources (for example, two kafka streams); it can also be very useful for bootstrapping, which is the process of processing historical data and then switching to a live stream.
For example, we can use union to combine two Kafka topics like this:
create table topic1 (
value TEXT
) WITH (
connector = 'kafka',
topic = 'topic1',
type = 'source',
bootstrap_servers = 'localhost:9092',
format = 'raw_string'
);
create table topic2 (
value TEXT
) WITH (
connector = 'kafka',
topic = 'topic2',
type = 'source',
bootstrap_servers = 'localhost:9092',
format = 'raw_string'
);
select value from topic1
union all select value from topic2;- Support UNION by @jacksonrnewhouse in #346
- Allow unions with matching types but different columns by @jacksonrnewhouse in #370
State compaction
Arroyo pipelines are stateful; operators like windows and joins need to remember things in order to aggregate across time, and sources and sinks need to remember what data they’ve already read or written to provide exactly-once semantics. While state is stored in memory for processing, it also needs to be written durably so that it can be recovered in the event of a failure. Today we write this state to local disk or to a remote object store like S3 as Parquet files.
This process of writing state to disk is called checkpointing (you can read more about how this works in our docs). Arroyo takes frequent checkpoints (by default every ten seconds) to minimize the amount of data that needs to be reprocessed in the case of failure. Arroyo’s checkpointing is incremental, which means that each checkpoint only contains the changes since the last checkpoint, but still involves writing a new set of files.
Parquet files are immutable, which means that if a value is overwritten or deleted, it remains in previous versions of the file. So over time, as we take more checkpoints, we end up with more and more files on disk, and more and more data that needs to be read and processed when we restart a pipeline.
To solve this problem, Arroyo now supports compaction, which is the process of merging multiple Parquet files into a single file. By compacting our state files, we can actually delete data, and resolve multiples writes to the same key into a single value while reducing the total number of files.
Compaction is disabled by default for this release, but you can enable it by setting the COMPACTION_ENABLED env var to true. Some workloads will not benefit from compaction, but for others it can significantly reduce the storage costs of checkpoints and improve recovery times.
- Allow compaction on previously compacted epochs by @jbeisen in #328
- Smoke test compaction and fix compaction logic by @jbeisen in #332
- Support delete operations for KeyTimeMultiMap by @jbeisen in #338
- Support deletes in the parquet backend by @jbeisen in #282
Arroyo CLI
Arroyo now includes a CLI tool, arroyo, which currently can be used to manage local Arroyo clusters. If you have a rust toolchain, you can install it with
$ cargo install arroyo
$ arroyo
Arroyo is a distributed stream processor that lets users ask complex
questions of high-volume real-time data by writing SQL.
This CLI can be used to run Arroyo clusters in Docker
Usage: arroyo <COMMAND>
Commands:
start Starts an Arroyo cluster in Docker
stop Stops a running Arroyo cluster
help Print this message or the help of the given subcommand(s)
Options:
-h, --help Print help
-V, --version Print versionThen you can start an Arroyo cluster with
$ arroyo startWe’ll be adding more commands to the CLI in the future, including support for interacting with the API to manage pipelines and run queries.
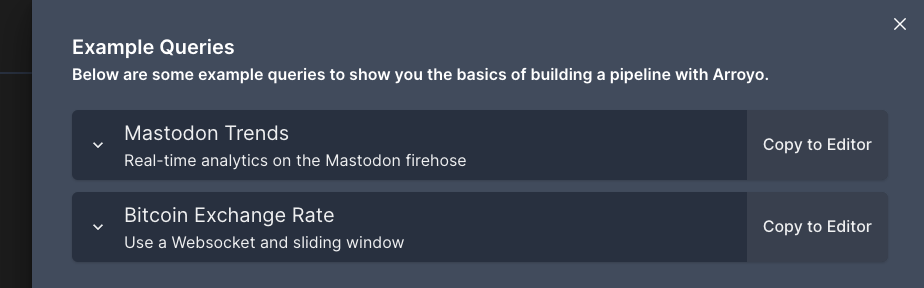
Console onboarding and example queries
The console will now lead you through a short tour of the system when you first open it, and includes a set of example queries to get you started. The example queries can be found by clicking the “book” icon in the top right of the create pipeline screen.
UDF checking in the console
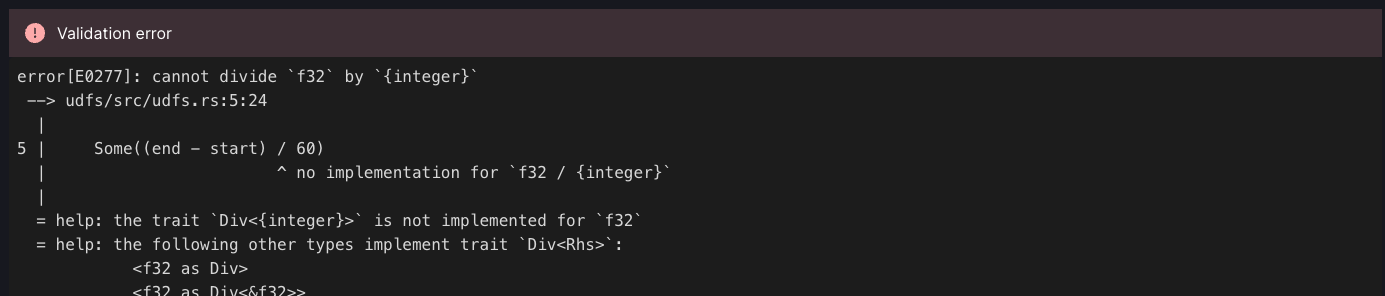
When writing Rust UDFs, it’s easy to end up with compiler errors as you’re developing. Arroyo now checks UDFs for errors before starting the pipeline, and will show you the errors in the console:
Array indexing
Arroyo now supports indexing into arrays with subscript notation:
select make_array(1, 2, 3)[1]
from source;- Support numeric indexes off of arrays by @jacksonrnewhouse in #364
Custom consumer groups for Kafka
The Kafka source now supports setting a custom consumer group name, which can be useful when relying on Kafka’s built-in offset tracking to start a new pipeline from where a previous pipeline left off. Note that running multiple concurrent pipelines with the same consumer group will result in each pipeline only receiving a subset of the data.
The consumer group for a Kafka source can be set in the console, or in SQL with the group_id option:
create table source (
value TEXT
) WITH (
connector = 'kafka',
topic = 'topic',
type = 'source',
bootstrap_servers = 'localhost:9092',
format = 'raw_string',
group_id = 'my_consumer_group'
);- Adding support for custom consumer group by @harshit2283 in #325
Restarting failed pipelines
It’s now possible to restart a pipeline that has failed. Pipelines can fail for a number of reasons, including repeated problems talking to an external system, invalid data, or bugs in UDFs. When a pipeline fails the controller will attempt to restart it automatically, but if the problem persists it will eventually transition to the failed state and cease execution.
It’s now possible to restart such pipelines from the console or via the new /api/v1/pipelines/{id}/restart endpoint.
Improvements
- Refactor metrics registration by @jbeisen in #324
- Refactor state tables into their own modules by @jacksonrnewhouse in #329
- Bump fluvio to 0.21 by @jacksonrnewhouse in #336
- Making the raw identifier robust for numeric aliases by @edmondop in #331
- Writing to file:/// should write to absolute paths by @jacksonrnewhouse in #344
- Checkpointing: record end time of checkpointing by @jacksonrnewhouse in #343
- Remove arroyo-sql-testing’s dependency on the controller by @jbeisen in #349
- Do checkpoints in impulse source smoke tests by @jbeisen in #350
- Only generate builder types for source/sink data by @mwylde in #347
- Trigger checkpoints and restoring in smoke tests by @jbeisen in #330
- Trigger builds on prs by @jbeisen in #341
- Don’t finish pipeline on websocket reset by @mwylde in #361
- Add session window smoke tests by @jbeisen in #353
- Add regex dependency to UDF crate by @mwylde in #368
- Don’t convert select distinct into an update by @mwylde in #367
- Update dependencies to address dependabot alerts by @mwylde in #369
- Bump @babel/traverse from 7.22.5 to 7.23.2 in /arroyo-console by @dependabot in #371
- Update with new branding by @mwylde in #372
Fixes
- Helm: fix the api replicas parameter name by @haoxins in #351
- Cleanup workers in finished state by @mwylde in #355
- Fix regression in parsing fields that are not valid Rust idents by @mwylde in #358
- Generate serializer items for json schema by @mwylde in #362
Full Changelog: https://github.com/ArroyoSystems/arroyo/compare/v0.6.0…v0.7.0