

I’m excited to announce the release of Arroyo 0.5, the latest version of our open-source stream processing engine. This release is all about connectors: we’ve added a high-performance transactional FileSystem sink, exactly-once Kafka support, a Kinesis connector, and more.
Table of Contents
Overview
Arroyo 0.5 brings a number of new features and improvements to the Arroyo platform. The biggest of these is the new FileSystem connector, which is a high-performance, transactional sink for writing data to filesystems and object stores like S3. This allows Arroyo to write into data lakes and data warehouses. We’ve also added exactly-once support for Kafka sinks, a new Kinesis connector, expanded our SQL support, and made a number of improvements to the Web UI and REST API.
Read on for more details, and check out our docs for full details on existing and new features.
Thanks to all our contributors for this release:
What’s next
With 0.5 out the door we’re already hard at work on the next release, targeted for early September. The headline feature for 0.6 will be what we call event-history joins, which allow you to join new events against the entire history data for a given key—for example, when a user transaction comes in you can join against all of that user’s previous activity.
Building on the FileSystem work in this release, we’ll also be adding integration with Delta Lake. Along with a new, built-in Postgres sink we’ll be expanding Arroyo’s capabilities for ETL workloads. Finally, we’re planning on introducing our first support for UDAFs (user-defined aggregate functions), to allow more powerful extensions to Arroyo’s SQL support.
Anything else you’d like to see? Let us know on Discord!
Now on to the details.
Features
FileSystem connector
Columnar files (like Parquet) on S3 have become the de-facto standard for storing data at rest, combining low cost of storage with decent query performance. Modern query engines like Trino, ClickHouse, and DuckDB can operate directly on these files, as can many data warehouses like Snowflake and Redshift.

And with the new FileSystem connector, Arroyo can efficiently perform real-time ETL into these S3-backed systems.
The FileSystem connector is a high-performance, transactional sink for writing data (as Parquet or JSON files) to file systems and object stores like S3.
It’s deeply integrated with Arroyo’s checkpoint system for exactly-once processing. This means that even if a machine is lost or a job is restarted, the data written to S3 will be consistent and correct. Unlike other systems like Flink, it’s even able to perform consistent checkpointing while in the process of writing a single Parquet file. This means that you can write larger files for better query performance while still performing frequent checkpoints.
Look out for a blog post in the near future with more details on how all of this works.
FileSystem sinks can be created in SQL via a CREATE TABLE statement like this:
CREATE TABLE bids (
time timestamp,
auction bigint,
bidder bigint,
price bigint
) WITH (
connector ='filesystem',
path = 'https://s3.us-west-2.amazonaws.com/demo/s3-uri',
format = 'parquet',
parquet_compression = 'zstd',
rollover_seconds = '60'
);See the docs for all of the details and available options.
- Commits and parquet file sink by @jacksonrnewhouse in #197
- Add Parquet as a serialization format throughout by @jacksonrnewhouse in #216
Exactly-once Kafka sink
Arroyo has always supported exactly-once processing when reading from Kafka by integrating offset-tracking with its checkpoint system. In 0.5 we’re adding exactly-once support for writing to Kafka as well. This enables end-to-end exactly-once processing when integrating with other systems via Kafka.
Exactly-once processing is achieved by leveraging Kafka’s transactional API. When processing starts, Arroyo will begin a transaction which is used for all writes.
Once a checkpoint is completed successfully, the transaction is committed, allowing consumers to read the records. This ensures that records are only read once, even if a failure occurs.
If a failure does occur, the transaction will be rolled back and processing will restart from the last checkpoint.
Exactly-once Kafka sinks can be created in SQL via a CREATE TABLE statement by configuring the new 'sink.commit_mode' = 'exactly_once' option, for example:
CREATE TABLE sink (
time TIMESTAMP,
user_id TEXT,
count INT
) WITH (
connector ='kafka',
topic = 'results',
bootstrap_servers = 'localhost:9092',
type = 'sink',
format = 'json',
'sink.commit_mode' = 'exactly_once'
);There is also now a corresponding source.read_mode option for Kafka sources, which can set to read_committed to read only committed records produced by a transactional producer.
See the Kafka connector docs for more details.
- implement exactly-once commits to Kafka sinks and read_committed reads to Kafka sources by @jacksonrnewhouse in #218
Kinesis connector
Arroyo now supports reading from and writing to AWS Kinesis data streams via the new Kinesis connector. Like the existing Kafka connector, the Kinesis connector supports exactly-once processing of records.
Kinesis sources and sinks can be created in the Web UI or via SQL, for example
CREATE TABLE kinesis_source (
time TIMESTAMP,
user_id TEXT,
count INT
) WITH (
connector ='kinesis',
stream_name = 'my-source',
type = 'source',
format = 'json'
);
CREATE TABLE kinesis_sink (
time TIMESTAMP,
user_id TEXT,
count INT
) WITH (
connector ='kinesis',
stream_name = 'my-sink',
type = 'sink',
format = 'json'
);
INSERT INTO kinesis_sink
SELECT * from kinesis_source;See the Kinesis connector docs for all the available options.
- Add Kinesis Source and Sink by @jacksonrnewhouse in #234
Postgres sink via Debezium
Arroyo now supports writing to relational databases (including Postgres and Mysql) via Debezium.
As part of this work, we’ve added support for embedding JSON schemas in outputs in Kafka Connect format. This allows integration with Kafka Connect connectors that, like Debezium, require a schema.
See the Postgres connector docs for the details.
We’ve also improved our format system to allow for more control over how data is serialized and deserialized, for example allowing for custom date and timestamp formats. Refer to the new format docs.
Session windows
Arroyo 0.5 adds support for session windows.
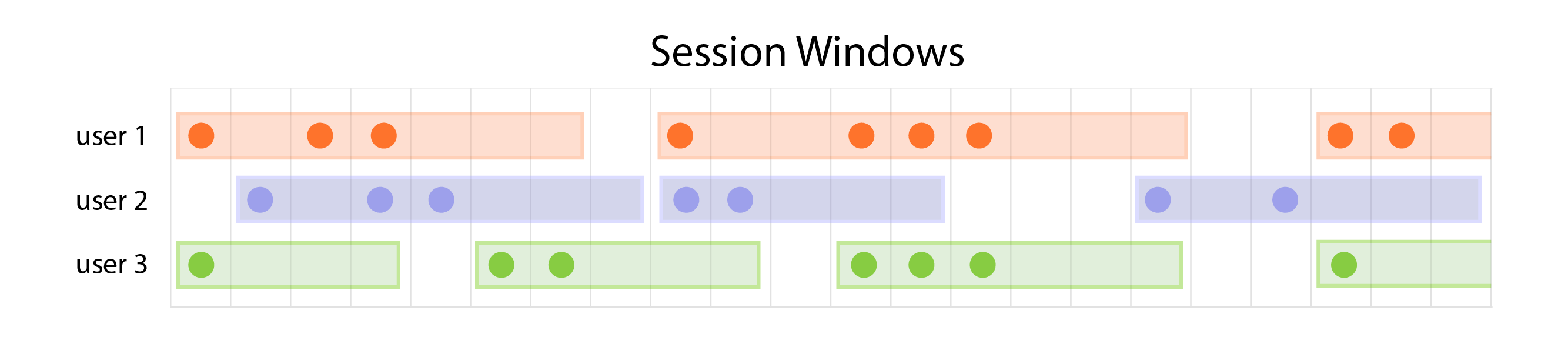
An example session window with gap size of 3; the window is closed when no records for a particular user are received for 3 seconds.
Unlike sliding and tumbling windows which divide time up into fixed intervals, session windows are defined by a gap in time between records. This is often useful for determining when some period of activity has finished and can be analyzed.
For example, let’s take a query over user events on an ecommerce site. A user may arrive on the site, browse around, add some items to their cart, then disappear. A day later they may return and complete their purchase. With session windows we can independently (and efficiently) analyze each of these sessions.
We can create a session window using the session function, which takes as an argument that gap time:
SELECT
session(INTERVAL '1 hour') as window,
user_id,
count(*)
FROM clickstream
GROUP BY window, user_id;Idle watermarks
Partitioned sources (like Kafka or Kinesis) may experience periods when some partitions are active but others are idle due to the way that they are keyed. This can cause delayed processing due to how watermarks are calculated: as the minimum of the watermarks of all partitions.
If some partitions are idle, the watermark will not advance, and queries that depend on it will not make progress. To address this, sources now support a concept of idleness, which allows them to mark partitions as idle after a period of inactivity. Idle partitions, meanwhile, are ignored for the purpose of calculating watermarks and so allow queries to advance.
Idleness is now enabled by default for all sources with a period of 5 minutes. It can be configured when creating a source in SQL by setting the idle_micros options, or disabled by setting it to -1.
A special case of idleness occurs when there are more Arroyo source tasks than partitions (for example, a Kafka topic with 4 partitions read by 8 Arroyo tasks). This means that some tasks will never receive data, and so will never advance their watermarks. This can occur as well for non-partitioned sources like WebSocket, where only a single task is able to read data. Now sources will immediately set inactive tasks to idle.
REST API
Continuing the work started in 0.4, we are migrating our API from gRPC to REST. This release includes a number of new endpoints, and can now be used to fully manage pipelines and jobs.
For example, let’s walk through creating a new pipeline:
curl http://localhost:8000/api/v1/pipelines \
-X POST -H "Content-Type: application/json" \
--data @- << EOF
{
"name": "my_pipeline",
"parallelism": 1,
"query": "
CREATE TABLE impulse (
counter BIGINT UNSIGNED NOT NULL,
subtask_index BIGINT UNSIGNED NOT NULL
)
WITH (
connector = 'impulse',
event_rate = '100'
);
SELECT * from impulse;",
"udfs": []
}
EOF
{
"id": "pl_W2UjDI6Iud",
"name": "my_pipeline",
"stop": "none",
"createdAt": 1692054789252281,
...
}Each pipeline has one or more jobs, which are the running instances of the pipeline. We can list the jobs for a pipeline:
curl http://localhost:8000/api/v1/pipelines/pl_W2UjDI6Iud/jobs | jq '.'
{
"data": [
{
"id": "job_Tqkow4Uc4x",
"runningDesired": true,
"state": "Running",
"runId": 1,
"startTime": 1692054798235781,
"finishTime": null,
"tasks": 4,
"failureMessage": null,
"createdAt": 1692054789252281
}
],
"hasMore": false
}Once we’re done, we can stop the pipeline:
curl http://localhost:8000/api/v1/pipelines/pl_W2UjDI6Iud \
-X PATCH \
-H "Content-Type: application/json" \
-d '{"stop": "checkpoint"}'See all of the API docs here.
In this release most of the Web UI has been migrated from the gRPC API to the new REST API along with a number of improvements to the UI.
- Use REST API for majority of console by @jbeisen in #221
- Stream job output using server-sent events by @jbeisen in #228
- Use REST API for metrics by @jbeisen in #229
- Fix action button behavior by @jbeisen in #232
- Move rest types to arroyo-rpc by @jbeisen in #230
- Use REST API for connectors by @jbeisen in #231
- Proxy api requests and allow setting api root by @jbeisen in #236
- Show API unavailable page on 5xx responses by @jbeisen in #238
- Show warning message if we can’t get metrics by @jbeisen in #249
- Backfill pub_id columns by @jbeisen in #219
- Unify job ids by @jbeisen in #223
- Use jobs tag with metrics endpoint by @jbeisen in #247
Improvements
- Adding global error handling by @edmondop in #206
- Validating table name by @edmondop in #207
- Update dependencies by @mwylde in #211
- Address GitHub dependabot alerts by @mwylde in #212
- Improvements to node scheduler by @mwylde in #213
- Implement the from_unixtime SQL function by @mwylde in #217
- Bump datafusion to 28.0.0. Move arrow-rs up to workspace level by @jacksonrnewhouse in #220
- Report errors instead of panicking when we receive invalid debezium messages by @mwylde in #245
- Build services with —all-features for arroyo-single by @jacksonrnewhouse in #246
- Make udfs field optional in REST API by @jbeisen in https://github.com/ArroyoSystems/arroyo/pull/250
Fixes
- Fix type for array builder on Float32 by @jacksonrnewhouse in #226
- Use correct PrimitiveBuilder for Float16 and Float64 by @jacksonrnewhouse in #227
- Fix job output rendering by @jbeisen in #244
- Fix delete pipeline query and check job status by @jbeisen in #210
- Correctly constrain sql calculations by @jacksonrnewhouse in #241
- Restore raw string deserialization by @jbeisen in #248
- build services with —all-features for arroyo-single. by @jacksonrnewhouse in https://github.com/ArroyoSystems/arroyo/pull/246
The full change-log is available here