

The Arroyo team is thrilled to announce general availability for Arroyo 0.10. This release is our biggest ever. Since 0.9, we’ve completely rebuilt the core SQL engine around Apache Arrow and the DataFusion SQL toolkit.
Why did we do this? Well in short:
- Throughput: 3x higher
- Pipeline startup: 20x faster
- Docker image size: 11x smaller
- SQL functions: 4x more
This release also radically simplifies the Arroyo architecture. The entire system now compiles to a single binary that can be flexibly deployed on a single machine, simple container orchestration platforms like Fargate, and scalable distributed runtimes like Kubernetes.
For way more detail on how we got here and why we’re making this change, see our migration announcement blog post.
While most of our focus has been on the migration, we still have a few new features and two new connectors contributed by our amazing community.
Want to try it out? Getting started is as easy as running
docker run -p 8000:8000 ghcr.io/arroyosystems/arroyo-single:0.10We’re very happy to welcome several new contributors to the Arroyo project:
- @bakjos, who contributed the MQTT connector
- @gbto, who contributed the NATS connector
- @FourSpaces, who contributed bug fixes to helm
And thanks to everyone else who helped with this release!
Table of Contents
New Connectors
NATS
NATS is a messaging and queueing system designed for simplicity and performance. Arroyo 0.10 adds sources and sinks for Core NATS and NATS Jetstream, which layers on persistence and delivery guarantees.

For example, to consume from a NATS stream, we can use this DDL:
CREATE TABLE logs (
id BIGINT NOT NULL,
time TIMESTAMP NOT NULL,
host TEXT NOT NULL,
level TEXT NOT NULL,
message TEXT NOT NULL
) with (
type = 'source',
connector = 'nats',
servers = 'localhost:4222',
subject = 'logs',
'auth.type' = 'credentials',
'auth.username' = '{{ NATS_USER }}',
'auth.password' = '{{ NATS_PASSWORD }}',
format = 'json'
);See the connector docs for more details.
Thanks to Quentin Gaborit for this incredible contribution!
MQTT
MQTT is a lightweight messaging protocol widely used with low-power devices and in the Internet of Things (IoT) space. Arroyo 0.10 now ships with an MQTT source and sink to consume and produce from MQTT brokers.

For example, you can create an MQTT source with the following SQL
CREATE TABLE devices (
device_id BIGINT NOT NULL,
time TIMESTAMP NOT NULL,
lat FLOAT NOT NULL,
lng FLOAT NOT NULL,
metadata JSON
) with (
connector = 'mqtt',
url = 'tcp://localhost:1883',
type = 'source',
topic = 'events',
format = 'json'
);See the connector docs for more details.
Thanks to community member Giovanny Gutiérrez (@bakjos) for this amazing contribution!
$ arroyo
With the new architecture in 0.10, the entire Arroyo system now builds as a single binary
$ arroyo
Usage: arroyo <COMMAND>
Commands:
api Starts an Arroyo API server
controller Starts an Arroyo Controller
cluster Starts a complete Arroyo cluster
worker Starts an Arroyo worker
compiler Starts an Arroyo compiler
node Starts an Arroyo node server
migrate Runs database migrations on the configure Postgres database
help Print this message or the help of the given subcommand(s)
Options:
-h, --help Print help
-V, --version Print versionRunning a complete local cluster is as easy as
$ arroyo cluster
INFO arroyo_controller: Using process scheduler
INFO arroyo_server_common: Starting cluster admin server on 0.0.0.0:8001
INFO arroyo_controller: Starting arroyo-controller on 0.0.0.0:9190
INFO arroyo_api: Starting API server on 0.0.0.0:8000
INFO arroyo_compiler_service: Starting compiler service at 0.0.0.0:9000Today we are providing pre-compiled binaries on the release page for Linux and MacOS, or you can build your own by following the dev instructions.
Note that Arroyo currently requires a running Postgres database for configuration, but in the next release we will be adding the option of using sqlite. Prometheus is also used to power the pipeline metrics in the Web UI if available.
Performance
Arroyo 0.10 is significantly faster than 0.9:

Benchmarks comparing Arroyo 0.10.0 to 0.9.1. In all cases, JSON-encoded Nexmark data was read from a Redpanda source. Query numbers refer to Nexmark benchmarks. Benchmarks run on a C7i.4xlarge.
In fact, it’s so fast that for many benchmarks we’ve run on EC2 instances, it can saturate the network before using all the available CPU. We’ll be following up with rigorous benchmarks against other systems, but in early tests it significantly beats other streaming systems in throughput.
How has it gotten so much faster? This is deserving of an entire blog post, but the short version is that Arroyo now operates internally on columnar data using carefully tuned vector kernels, thanks to the hard work of the Apache Arrow and DataFusion communities.
Columnar data is now the standard for OLAP (analytics-oriented) query engines like ClickHouse, Pinot, and Presto. There are a few reasons for this:
- By storing all values in a column together, you can achieve better compression ratios and make better use of CPU cache
- Only the columns actually referenced in a query need to be read, reducing disk and network IO
- Columnar processing aligns well with the vector capabilities in modern CPUs, providing 3x or more speedups
However, row-oriented data remains the standard for streaming engines. There are some inherent tradeoffs between latency (how quickly an event can traverse through the pipeline) and throughput (how many events can be processed with a given amount of CPU). By batching1 data we can get higher throughput at the expense of latency. And columnar representations require that we batch a number of events together before we see performance improvements (in fact, with a small number of rows columnar processing will be much slower due to fixed overhead).
But there’s a strong argument for moving to columnar representations for streaming: at any given batch size, the higher the throughput the less time we must wait to fill that batch. For example, if we want at least 100 records in our batch to overcome fixed costs, the amount of time we need to wait to receive 100 records will depend on our throughput:
- At 10 events/second, it takes 1 second
- At 1,000 — 0.01 seconds (100ms)
- At 1,000,000 — 0.0001 (0.1ms)
Or looking at it from a fixed latency perspective (say, waiting at most 10ms):
- At 10 events/second, our batch size is 1
- At 1,000 — 100
- At 1,000,000 — 100,000
In Arroyo 0.10, we perform batching at the source and via aggregating operators like windows and joins. The source batching behavior can be configured via two environment variables:
BATCH_SIZEwhich controls the maximum batch sizeBATCH_LINGER_MSwhich controls the maximum amount of time to wait (in milliseconds) before emitting a batch
By configuring these values, users can choose their own tradeoff between latency and throughput.
SQL Improvements
Functions
We’ve added support for over 200 new scalar, aggregate, and window SQL functions. These unlock many powerful new capabilities that previously would have been inexpressible or would have required writing a UDF.
There are too many new functions to highlight them all, but some exciting additions include:
- Nearly 200 scalar functions, covering math, conditions, strings, regex, JSON, date and time, and more
- Statistical and approximate aggregate functions like
approx_percentile_contandapprox_distinct,which uses HyperLogLog to produce very memory-efficient estimate distinct counts - Many new SQL window functions including rank, percent_rank, lag, and lead
Check out the Scalar, Aggregate, and Window function docs for the complete list.
Arrays
Previously, Arroyo supported a limited set of operations on arrays, but only within certain contexts. Now we have complete array support, including a comprehensive set of array function, support for indexing via square brackets (like a[1]), support for serializing arrays as JSON and Avro, the ability to convert aggregates into arrays (via array_agg), and the ability to unroll arrays into separate rows via unnest.
For example, we can write unique IPs over a tumbling window as an array to Kafka with a query like this:
CREATE TABLE sink (
values TEXT[]
) with (
connector = 'confluent',
connection_profile = 'confluent-working',
format = 'avro',
'avro.confluent_schema_registry' = 'true',
topic = 'list_output',
type = 'sink'
);
INSERT INTO sink
SELECT array_agg(DISTINCT ip) FROM logs
GROUP BY tumble(interval '10 seconds');Source Fusion
Arroyo 0.10 includes new optimizations that reduce the amount of data read from a single source when it’s used across multiple queries. Now, each source will only be read once rather than once per subquery.
This same optimization also applies to views, so compute can be reused across outputs.
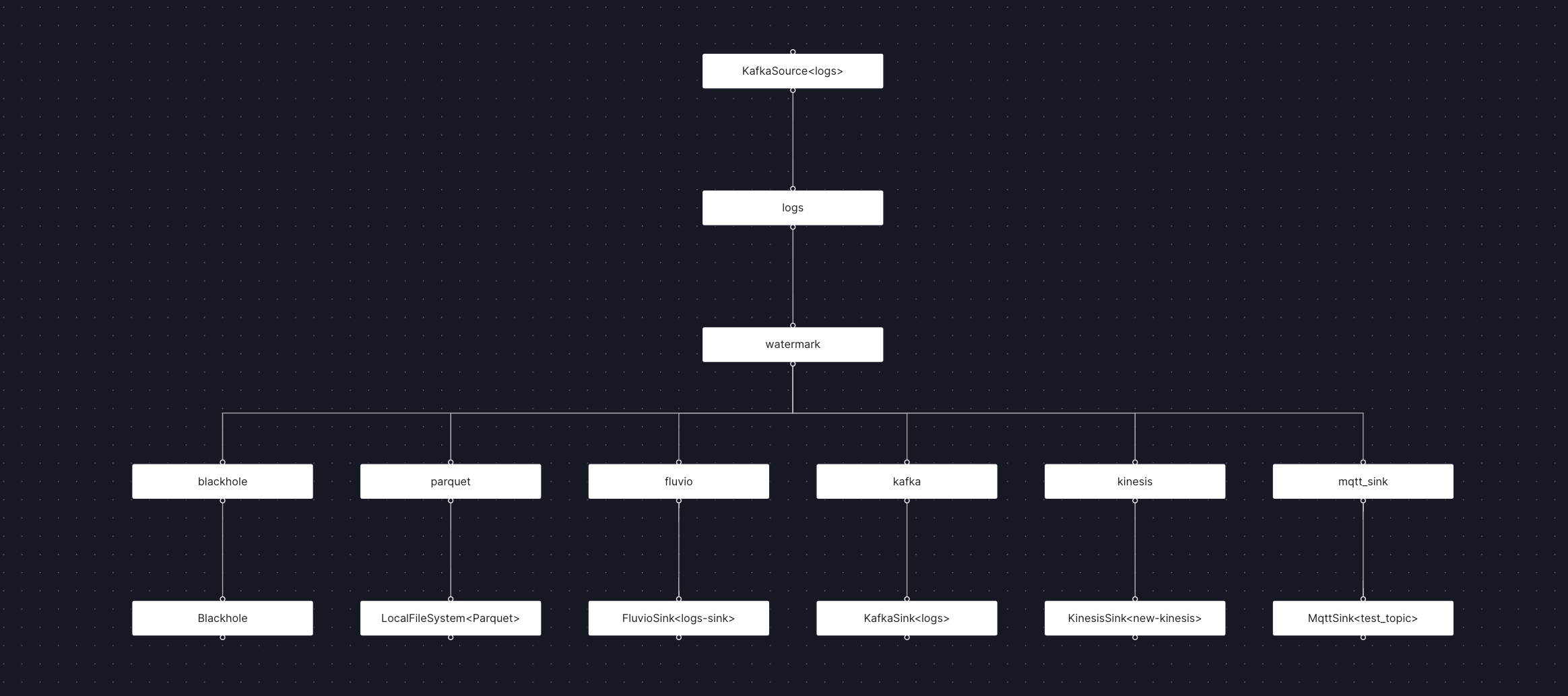
In case you ever wanted to replicate data from Kafka into (nearly) every supported Arroyo sink
Upgrading to 0.10
There are some backwards-incompatible changes in 0.10’s SQL. Some pipelines written for 0.9 will need to be updated as described here.
Virtual fields
The syntax for virtual fields has changed to more closely match Postgres: we now require the STORED keyword. Previously:
event_time TIMESTAMP GENERATED ALWAYS AS (CAST(date as TIMESTAMP))Now:
event_time TIMESTAMP GENERATED ALWAYS AS (CAST(date as TIMESTAMP)) STOREDUDFs
UDF definitions have changed slightly; now the UDF function must be annotated with an attribute macro #[arroyo_udf_plugin::udf], for example:
use arroyo_udf_plugin::udf;
#[udf]
fn plus_one(x: i64) -> i64 {
x + 1
}This change means we now support defining other helper functions within the UDF definition.
Additionally, async UDFs no longer support defining a Context struct; instead use a static OnceLock or tokio::sync::OnceCell to share resources between async UDF invocations.
Async UDF options are now specified in the #[udf()] attribute macro rather than in the toml comment, like
#[udf(ordered, allowed_in_flight=100, timeout="10s")]
async fn query_db(id: u64) -> String {
...
}See the async UDF docs for all of the details.
Update behavior
Previously, when using update tables every change would be output. In 0.10, changes are buffered for some amount of time to reduce the volume of outputs. This interval is by default 1 second, but can be configured via the UPDATE_AGGREGATE_FLUSH_MS environment variable.
See the update table docs for more details.
Improvements
- Operator / source trait redesign by @mwylde in #482
- Add methods in operator trait to allow polling arbitrary futures in the main select loop by @mwylde in #501
- Improve kafka client_config setting by @mwylde in #520
- Add embedded scheduler by @mwylde in #526
- Add support for custom schema registry subjects by @mwylde in #528
- Treat op type of ‘r’ as ‘c’ for Debezium deserialization by @jacksonrnewhouse in #539
- Add support for serializing avro lists by @mwylde in #576
- Make cargo clippy pass by @jacksonrnewhouse in #592
- Update dependencies to address dependabot alerts by @mwylde in #598
Fixes
- Upgrade framer-motion to fix UDF popover by @jbeisen in #499
- Pin openapi generator version by @mwylde in #559
- Fix a bug in the k8s deployment where the worker.slots configuration by @FourSpaces in #595
- Fix issue with multiple windows open to the pipeline editor by @mwylde in #593
Migration work
- Initial changes for migrating to RecordBatch/DataFusion compute by @jacksonrnewhouse in #459
- Bump to datafusion 34.0.0 and start on arroyo-df refactoring by @jacksonrnewhouse in #468
- Switch tumbling aggregator to be a two-parter by @jacksonrnewhouse in #470
- Arrow dataflow by @mwylde in #471
- Record batches/call on close by @jacksonrnewhouse in #472
- Arrow networking by @mwylde in #473
- Raw string format + sse and kafka sources by @mwylde in #474
- Arrow json decoding by @mwylde in #477
- Record batch table state by @jacksonrnewhouse in #475
- Add avro support for arrow deserializer by @mwylde in #481
- Implement smoke tests for record batching by @jacksonrnewhouse in #485
- Fix arroyo-types dependency for UDFs by @jbeisen in #495
- Don’t add _timestamp field to ArroyoSchemaProvider schemas, as they are also used for sinks by @jacksonrnewhouse in #498
- Windowing and state work by @jacksonrnewhouse in #497
- Json serialization and kafka sink by @mwylde in #500
- Use a better method for global tables so you don’t need to repeat by @jacksonrnewhouse in #502
- Migrate json_schema to arrow and remove old sql type system by @mwylde in #509
- Record batch session windows by @jacksonrnewhouse in #508
- Rewrite table scans as projections by @jbeisen in #507
- Generate watermarks and set event time using expressions by @jbeisen in #511
- Support non-windowed inner joins by @jacksonrnewhouse in #510
- Remove build cache by @mwylde in #513
- Connector migrations and redesign by @mwylde in #512
- Bump datafusion to 35 by @jacksonrnewhouse in #516
- Implement compaction for record batches by @jacksonrnewhouse in #515
- Maintain projections in source rewriter by @jbeisen in #518
- Arroyo-df: nested aggregations by @jacksonrnewhouse in #517
- Refactor filesystem source by @jacksonrnewhouse in #519
- Implement unnest in arrow land by @mwylde in #521
- Record batch old cleanup by @jacksonrnewhouse in #522
- Add JSON functions to datafusion branch by @mwylde in #525
- Change handle_watermark() method to return Watermark to broadcast by @jacksonrnewhouse in #527
- Load dynamically linked UDF libraries at runtime by @jbeisen in #523
- Filesystem Sink + Two Phase Commits by @jacksonrnewhouse in #524
- Fix panic when converting from ArrowProgram to LogicalProgram by @jbeisen in #531
- Docker and k8s for arrow branch by @mwylde in #529
- Migrate nexmark by @mwylde in #530
- Rework SourceRewriter and TimestampRewriter to preserve table scan aliases by @jacksonrnewhouse in #532
- Use hash of UDF definition for saving libraries by @jbeisen in #534
- Windowed Joins by @jacksonrnewhouse in #533
- working smoketest by @jacksonrnewhouse in #535
- Add UDF compilation support to docker images by @mwylde in #538
- Support vector arguments in UDFs by @jbeisen in #540
- Avro and raw_string serialization by @mwylde in #541
- Update smoke tests by @mwylde in #544
- Overhaul DataFrame plannning to use DataFusion Extensions by @jacksonrnewhouse in #542
- Implement views for datafusion by @jacksonrnewhouse in #545
- Use table name for virtual field qualifier by @jacksonrnewhouse in #546
- Add more SQL plan tests by @mwylde in #547
- Df restructure extensions by @jacksonrnewhouse in #548
- Make key_indices optional to distinguish from an empty group by and no group by by @jacksonrnewhouse in #552
- Delta Lake + Bump DataFusion to 36.0 by @jacksonrnewhouse in #551
- Report correct metrics for record batches by @mwylde in #554
- Reset ExecutionPlans by @jacksonrnewhouse in #553
- Fix json decoding when BATCH_SIZE is greater than 1024 by @mwylde in #555
- Implement window functions over already windowed inputs by @jacksonrnewhouse in #563
- Remove arroyo-macros package by @jacksonrnewhouse in #564
- Restore reporting of checkpoint sizes in bytes by @jacksonrnewhouse in #565
- Drop old checkpoint rows from database by @jacksonrnewhouse in #569
- Refactor smoke test implementation to use .sql files by @jacksonrnewhouse in #570
- Fix regression in kafka producer that panicked on key serialization by @mwylde in #574
- Support bad_data=drop for arrow-json by @mwylde in #573
- Apply unnest to views by @jacksonrnewhouse in #579
- Use future::pending if tumbling aggregate’s FuturesUnordered is empty by @jacksonrnewhouse in #580
- Implement UDAFs on datafusion by @mwylde in #581
- Use format for SingleFileSourceFunc by @jacksonrnewhouse in #582
- Gracefully handle panics in UDFs by @mwylde in #584
- Support reinvocation of hop and tumble window functions in nested aggregates by @jacksonrnewhouse in #583
- Add support for configuring timestamp serialization format by @mwylde in #585
- Migrate node scheduler to arrow by @mwylde in #587
- Compute features for DataFusion Programs by @jacksonrnewhouse in #589
- Support memory tables in SQL by @jacksonrnewhouse in #590
- Async UDFs for datafusion by @mwylde in #591
- Non-windowed updating aggregates using datafusion by @jacksonrnewhouse in #588
- Check that time window functions (hop, tumble, session) are moved into operators by @jacksonrnewhouse in #594
- Fix a bug in the k8s deployment where the worker. slots configuration… by @FourSpaces in #595
- Fix sliding window data expiration by @jacksonrnewhouse in #596
- Add flushing behavior for Fluvio, Kinesis, and WebSocket sources by @jacksonrnewhouse in #597
- Compute union inputs in separate nodes by @jacksonrnewhouse in #599
- Write program to file instead of environment variable by @mwylde in #600
- Make the flush interval on updating aggregates configurable by @jacksonrnewhouse in #601
- Helm chart fixes for UDFs by @mwylde in #602
- Embed static files in binary for release builds by @mwylde in #603
Full Changelog: https://github.com/ArroyoSystems/arroyo/compare/v0.9.1…v0.10.0
Footnotes
Some engines like Spark Streaming operate on micro-batches, which sound similar but are quite different. In a micro-batch engine, the input is broken up into groups of data, each of which is processed as an independent batch job. Whereas in pure streaming systems like Flink and Arroyo, batching is purely a performance optimization and doesn’t affect the semantics of the system. ↩