

As the year comes to a close, the team has been reflecting on the past year of building the Arroyo streaming engine. At the start of the year the company was just a few months old. We had built a prototype that implemented the basic distributed dataflow and supported a very limited subset of SQL. And we hoped you liked Kafka, because that was the only available source.
One year later and Arroyo is a thriving open-source project with a production-quality distributed dataflow implementation, a plethora of connectors to other systems, and comprehensive support for streaming SQL.
This year we joined the Y Combinator W23 batch, launched our cloud product, open-sourced the engine, and did 8 releases. Along the way hundreds of folks have run pipelines, and we’ve helped a number of companies transition to real-time and off of legacy streaming systems like Flink.
The numbers
We’re all about data, so let’s start with some numbers!

Since open-sourcing in April, we’ve had:
- 12 contributors
- 2,841 Github ⭐️s
- 315 Discord members
- 100 issues filed
- 80k+ docker image pulls
- 342 PRs merged
- 8 minor releases (plus 4 patch releases)
We’re so grateful to everyone who’s contributed to the project, filed issues, and tried out Arroyo!
The UI
I thought it’d be fun to take a look at the state of the product a year ago.
The web console looks better than I’d remembered, for which we mostly have Chakra UI to thank—it lets even distributed systems engineers build a well-styled web app.
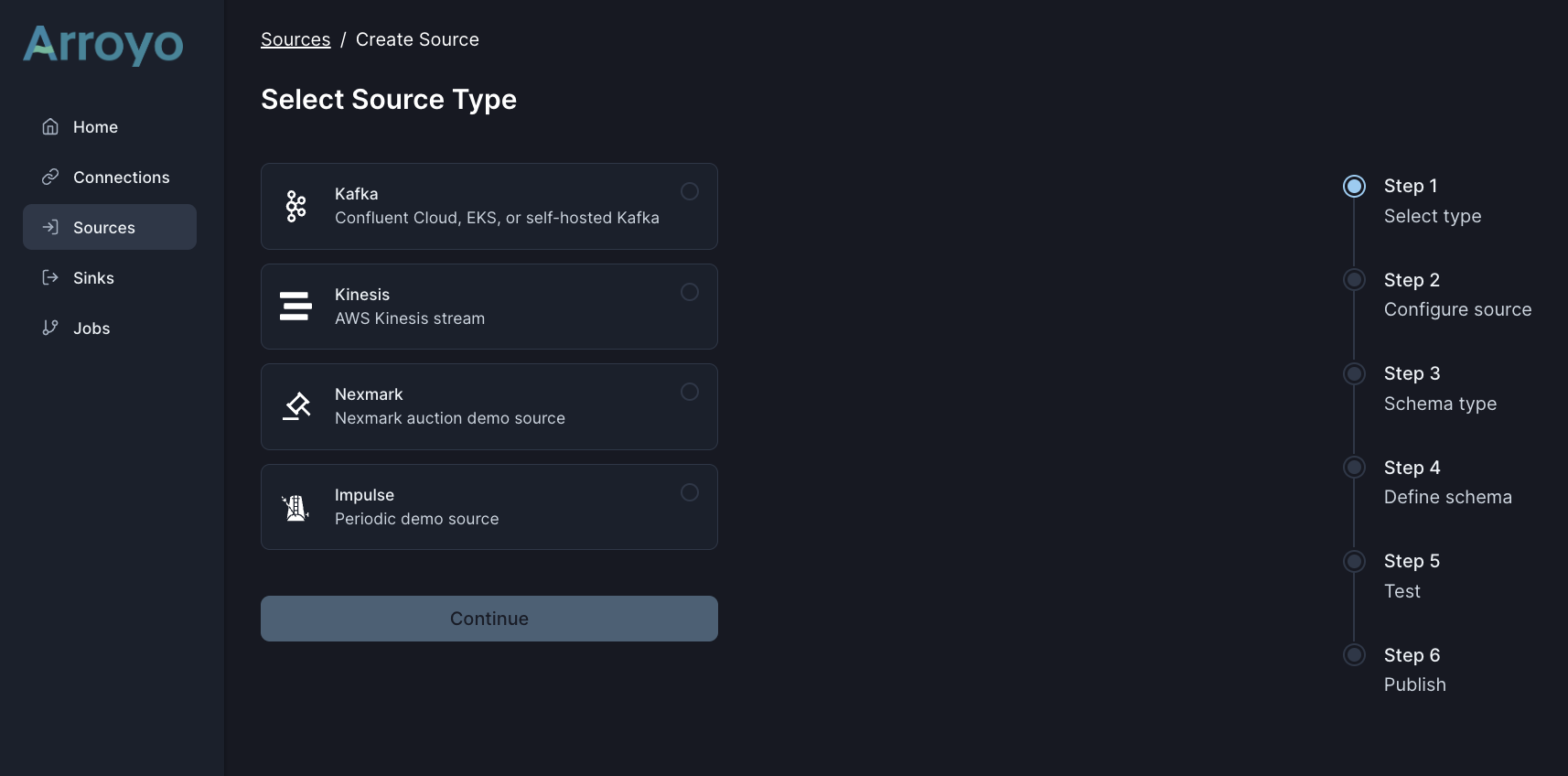
Arroyo as of 1/1/2023. The source creation UI optimistically listed Kinesis as an option, but it took another 6 months for the Kinesis connector to be actually built.
On the other hand, the pipeline creation UI has come a ways, with a real catalogue, support for UDFs, better error reporting, and preview support:
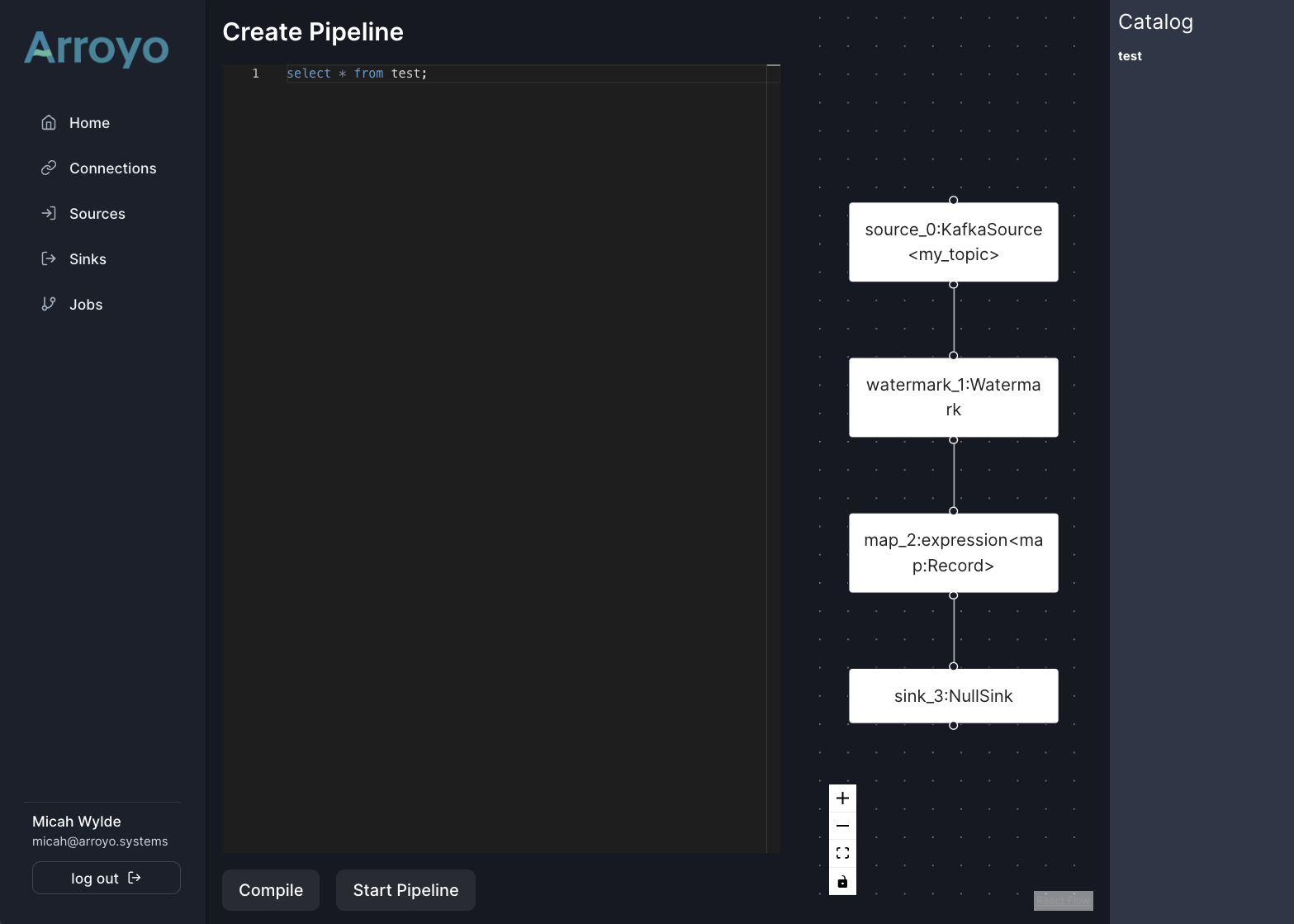
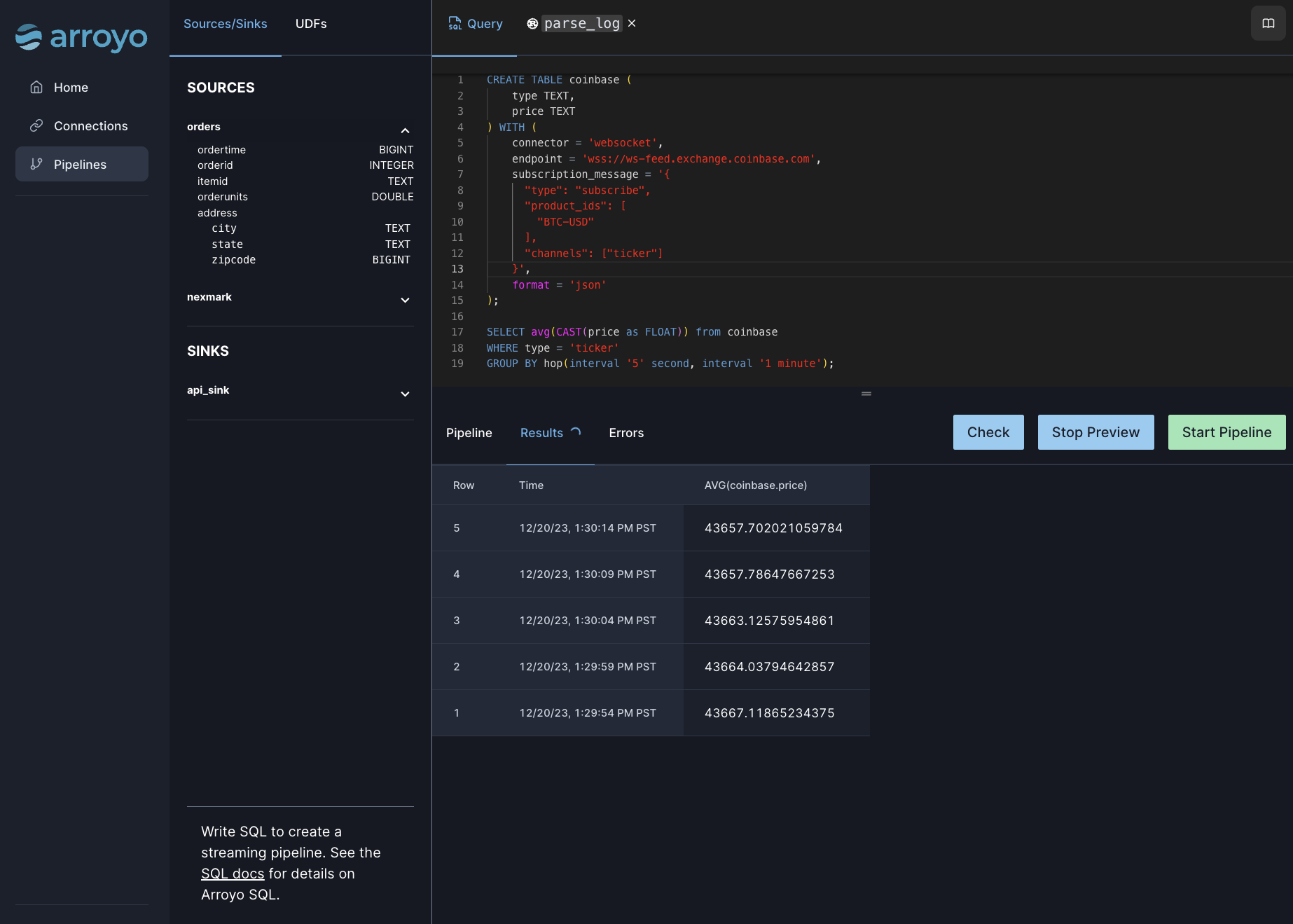
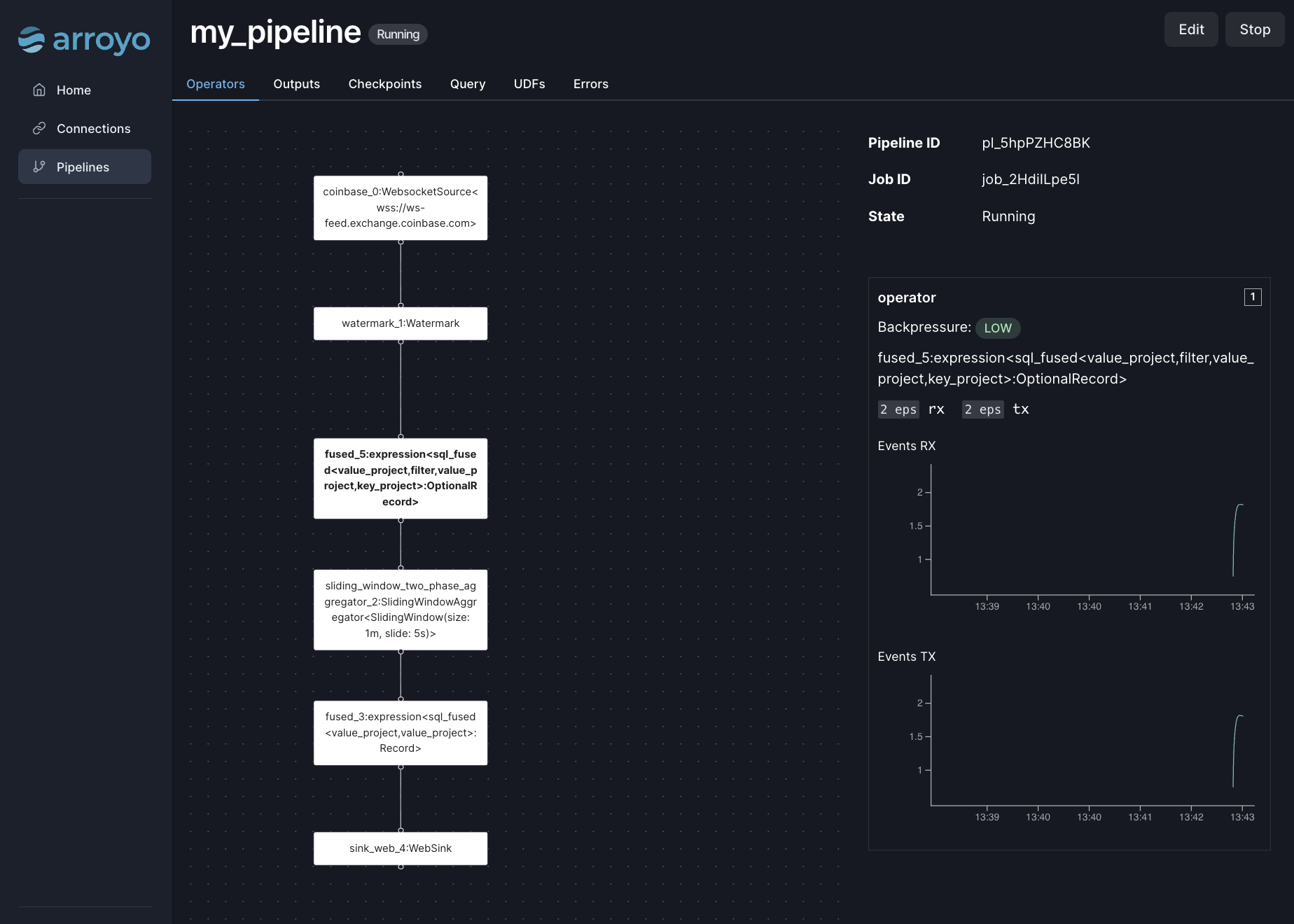
While the pipeline UI actually hasn’t changed much, aside from some new tabs and more controls:
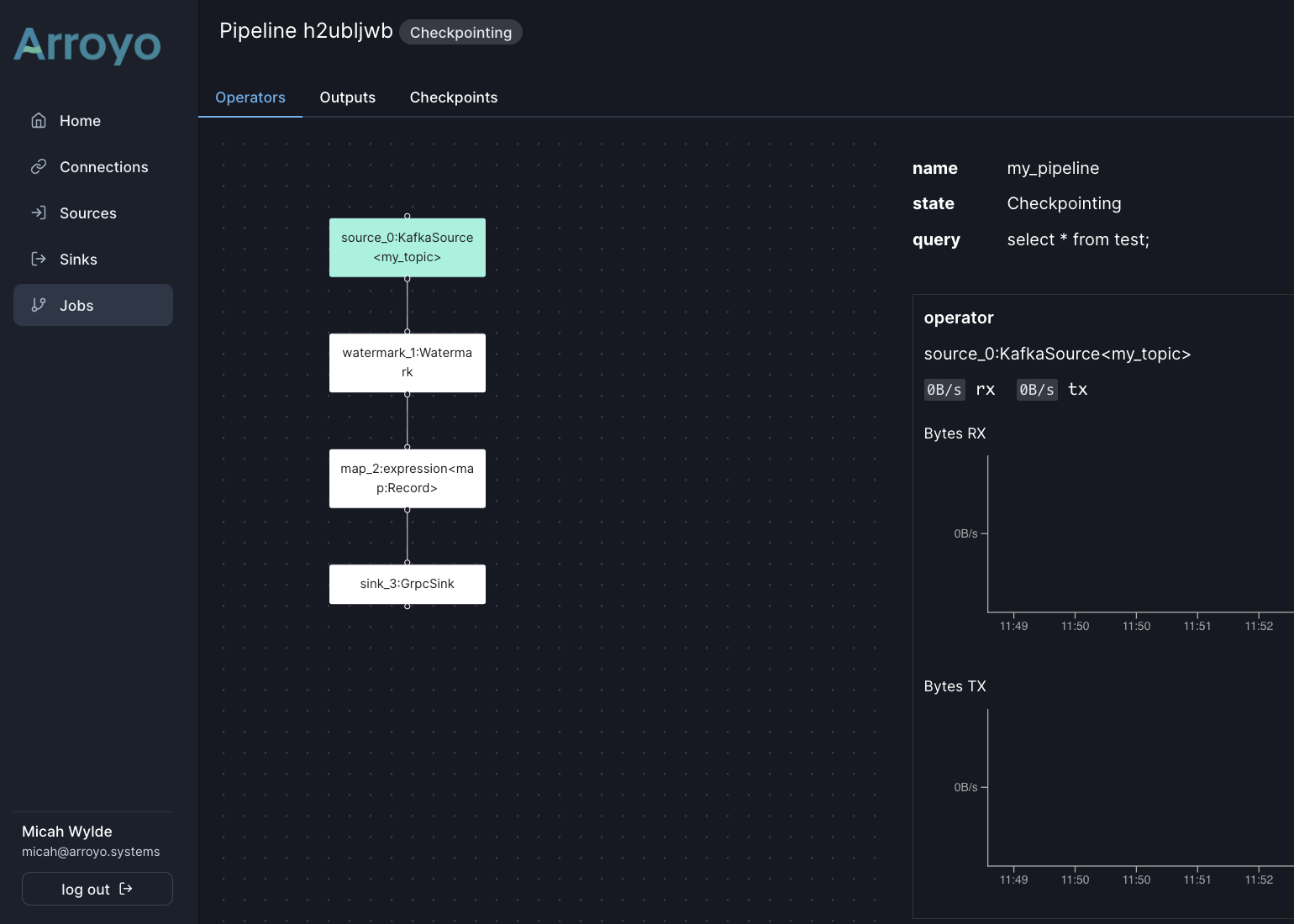
The Releases
Since the Arroyo 0.1 release in April we’ve released new 7 versions, up to 0.8 in November (along 3 patch releases).
- Arroyo 0.2 added Kubernetes support, many SQL functions, non-windowed joins, and support for changing pipeline parallelism
- Arroyo 0.3 added SQL DDL statements, UDFs, custom event times and watermarks, and the Server-Sent Events source
- Arroyo 0.4 added support for update tables, a redesigned connectors system and IO, Fluvio and Websocket connectors, and a REST API
- Arroyo 0.5 added the FileSystem sink, an exactly-once Kafka sink, Kinesis, Debezium, and session window
- Arroyo 0.6 added Google Cloud Storage support, UDAFs, SQL correctness tests, HTTP source and webhook sink
- Arroyo 0.7 added custom partitioning for the FileSystem sink, support for message framing, SQL unnest and union, state compaction, and showing UDF compile errors in the console
- Arroyo 0.8 added a FileSystem source and Delta Lake sink, a Redis sink, Avro support, schema inference, and global UDFs w
The contributors
We were thrilled to welcome a number of contributors to the project in addition to the core Arroyo team.

- Edmondo Porcu contributed several SQL features, improvements to console error handling, the helm chart, and our CI
- Xin Hao contributed a number of fixes and improvements to the helm chart and Kubernetes deployment
- R. Tyler Croy contributed FreeBSD support and doc fixes
- Ricardo Murillo contributed a FileSystem source and various bug fixes
- Alex Kennedy contributed several SQL functions
- Harshit contributed additional configuration options for the Kafka and FileSystem connectors
- Ari Seyhun contributed a fix to Redis configuration
- Lachlan Kermode contributed doc fixes
Thanks to everyone helping make Arroyo better by contributing code, documentation, and filing issues!
The blog posts
We wrote 21 blog posts (including this one!), with a combined 33,000 words. And more than 30,000 of you read them.

By far our most popular post was about our choice of programming language for Arroyo. The people clearly love Rust content!
Some other great posts from this year:
- 10x faster sliding windows: going into depth on how our sliding windows work and why that lets us be much faster than Flink for these queries
- Why not Flink?: a deep dive into why we decided to build a new stream processing engine instead of building on top of Apache Flink
- Streaming to S3 is surprisingly hard: a technical guide to how Arroyo’s S3 FileSystem sink is able to provide high-throughput, transactional writes with frequent checkpoints
- What is streaming SQL: which covers the different ways that streaming SQL engines think about converting batch queries into streaming pipelines and the underlying semantics
See you in 2024
We accomplished a lot in 2023, but we’re just getting started. We have big plans for the next year, including a massive upgrade to the engine, growing the company, and seeing many more Arroyo deployments out in the world.
If you’re interested in being part of that, reach out at founders@arroyo.systems.